行者无疆 始于足下 - 行走,思考,在路上
Emacs as a Python IDE
赋闲脱产的半年里,自己用C++/Java/Lisp胡乱写了几万行的代码,到了现在的公司,给OpenStack项目贴牛皮藓,反倒是Python用得最多。作为公司里面唯一的Emacser(没准也是 公司里JJ最长的吧,笑),我一直致力于在Emacs平台上折腾出一套顺手的Python开发环境,所幸有些小心得,付诸纸面,以飨大家。
Table of Contents
1 Python.el的选择
Emacs的python-mode有两套,一个是Emacs官方提供的python.el,另外一套是Python社区提供的python-mode.el。不过python.el和python-mode.el都有各种各样的小问题,python.el似乎是无法正确处理python的docstring,而python-mode.el的menu项太过繁杂,而且很多menu无法正确工作。这里用到的python.el来自于https://github.com/fgallina/python.el,细节可以参考水木社区的讨论。
安装方法可以参考项目主页的README,我自己针对el-get做了一个recipe,这样以后更新装卸都会方便很多,recipe如下:
(:name python
:website "https://github.com/fgallina/python.el"
:description "improved python.el from Fabián Ezequiel Gallina"
:type github
:pkgname "fgallina/python.el")
不过这个patch并没有被el-get接收,限于时间精力,我没有再去细究el-get撰写recipe的规范。
1.1 ipython集成
交互式的开发是python/ruby/lisp这类动态语言的重要特性,它让程序员从“编码-编译-运行-调试“的程序开发工程链中解放出来,从老旧的批处理是开发过渡到现代的交互式开发。如果你用过slime,你就会知道,交互式的开发不仅仅是一种开发模式,slime也不仅仅是一种工具,而是一种编程的革命。Emacs集成ipython,虽然没有slime那么强大,但是对于提高开发效率还是有莫大的帮助的。幸运的是,fgalling/python.el是支持ipython的。关于fgalling/python.el的参考设置如下:
(add-to-list 'load-path (expand-file-name
"~/.emacs.d/el-get/python"))
(require 'python)
(add-to-list 'auto-mode-alist '("\\.py\\'" . python-mode))
(setq
python-shell-interpreter "ipython2"
python-shell-interpreter-args ""
python-shell-prompt-regexp "In \\[[0-9]+\\]: "
python-shell-prompt-output-regexp "Out\\[[0-9]+\\]: "
python-shell-completion-setup-code
"from IPython.core.completerlib import module_completion"
python-shell-completion-module-string-code
"';'.join(module_completion('''%s'''))\n"
python-shell-completion-string-code
"';'.join(get_ipython().Completer.all_completions('''%s'''))\n")
常用快捷键:
- C-c C-z: (python-shell-switch-to-shell),切换至ipython解释器
- C-c C-c: (python-shell-send-buffer &optional ARG),发送整个buffer内容到ipython解释器运行
2 Emacs补全:Pymacs和Ropemacs
语言补全一直是Vim/Emacs这类上古"IDE"的弱项,每种语言都有自己的补全插件、配置方法和版本差异,而网上资料、特别是中文资料,或是陈旧潦草,或是语焉不详,常常让初学者们不知所措。本文所载内容恐怕两年左右就会过时,诸位看官高贤注意鉴别……
Emacs下的通用补全插件大概就是auto-complete和yasnippet了,前者可以做出基于buffer分词的补全,后者可以基于特定编程语言语法结构的补全。不过基于语义的补全,Emacs+Python下用的是pymacs和ropemacs。需要安装的有
- pymacs
- rope
- ropemacs
- ropemode
以上均可通过el-get安装。如若使用过程中出现莫名问题,不要纠缠,有可能是版本问题,无妨试验下用apt-get/pacman/yum安装。我本机上的配置如下:
;;; pymacs, rope and ropemacs
(add-to-list 'load-path "~/.emacs.d/el-get/pymacs")
(require 'pymacs)
(setq pymacs-load-path '("~/.emacs.d/el-get/rope"
"~/.emacs.d/el-get/ropemacs"))
;; Initialize Pymacs
(autoload 'pymacs-apply "pymacs")
(autoload 'pymacs-call "pymacs")
(autoload 'pymacs-eval "pymacs" nil t)
(autoload 'pymacs-exec "pymacs" nil t)
(autoload 'pymacs-load "pymacs" nil t)
;; Initialize Rope
(pymacs-load "ropemacs" "rope-")
(setq ropemacs-enable-autoimport t)
3 virtualenv
virtualenv是Python的sandbox(沙盒)。那么什么是sandbox呢?
在日常开发中我们常常碰到这样的场景:
- 需要针对不同的python library做测试(兼容性、性能等)
- 需要多人共享一台开发机
可是:
- 并不是所有人都有向系统PYTHONPATH安装python library的权限
- 我们常常需要同时安装多个不同版本的python library
而virtualenv通过一些脚本,通过软连接和修改环境变量的方式,提供了一个轻量级的虚拟python环境,在这里面个人可以按照自己意愿任意装卸配置library,也可以针对不同版本的library创建不同的virtualenv,方便的很。
3.1 virtualenvwrapper
virtualenv默认是在当前目录下建立一个.venv目录,但是这样有一个问题,就是virtualenv本身的管理很不方便,因为需要记忆不同的.venv的存放位置、具体用途等等。virtualenvwrapper则通过一些python和shell脚本,在virtualenv的基础上建立了一层抽象,实现了对virtualenv本身的统一管理。virtualenvwrapper会默认在$HOME/.virtualenvs目录下创建所有的virtualenv。
virtualenv和virtualenvwrapper均可以通过python pip安装:
pip install virtualenv virtualenvwrapper
常用命令:
- mkvirtualenv venv_name: 建立一个新的virtualenv,
- workon venv_name: 切换到venv_name这个virtualenv
3.2 virtualenv.el
virtualenv.el可以配合Emacs集成virtualenv,可以通过el-get安装。virtualenv.el需要virtualenv和virtualenvwrapper。
配置:
;; virtualenv support
(add-to-list 'load-path (expand-file-name
"~/.emacs.d/el-get/virtualenv"))
(require 'virtualenv)
常用命令:
- M-x virtualenv-workon: 切换virtualenv
4 Miscs
一些hook设置:
(add-hook 'python-mode-hook
(lambda ()
(ropemacs-mode)
(global-set-key (kbd "RET") 'newline-and-indent)
(auto-fill-mode 1)
(virtualenv-minor-mode 1)))
除了以上,Emacs中和Python开发有关的插件还可以有pylint、pep8、pyflakes等,参考文章:
- Configuring Emacs as a Python IDE
- Emacs as a powerful Python IDE
- Setup Perfect Python Environment In Emacs
- My Emacs Python environment
以上,抛砖引玉,希望能够对刚刚接触Linux/Python/Emacs的朋友有些许帮助。
Knight Rush——关于编程语言学习的一些思考
1 引子的引子
金庸小说里的大侠们在行走江湖时,向来都是衣来伸手饭来张口,一不小心心情郁闷了还可以来个金盆洗手、笑傲江湖,就是从来不会考虑钱的问题。我不是大侠,生活也不是小说,“退隐闭关”半年啃了几十本书后,生活还是要继续。这几日满京城地找工作,各种笔试面试聊技术聊人生,也让我对自己的技术体系和职业规划做了一次全盘扫描,快哉快哉。
2 引子
前几日面试了一家专注云计算的创业公司易云捷讯,一面是公司创始人 从美国打来的越洋电话,聊什么我已经记不太清楚了,其中有一道题目是关于Fibonacci数列的,这个恰好问到了我的G点上,于是我就将我在《SICP》 上学到的什么快速乘法啊、尾递归啊、迭代和递归啊啥的和盘托出,大大地吹嘘了一番,总之感觉还不错,算是了给面试官的一个小惊喜,就这样胡乱通过了一面。一面之后邮件沟通被分配了一道编程题目,大意如下1:
在一个国际象棋棋盘上(N*N),有一个棋子"马(Knight)",处在任意位置(x, y);马的走法是日字型,即其可以在一个方向上前进或后退两格,在另一方向上前进或后退一格。请编程找出马如何从位置(x, y)走到棋盘右下角(N, N)的位置的步骤。例如:假设棋盘大小为3*3,马处在(1,2)位置,马只需要走一步,即 (1,2)->(3,3)即可到达目的地。编程语言推荐的是Python,程序能输出一种可行的方法即可(无需找出所有方式),还有一些软件工程的要求诸如文档、注释、代码风格这些“无关痛痒”的东西。
我是第一次在应聘时碰到这种不限时间自由rush的题目,坦白的讲,我还是比较喜欢这种形式的题目的。纸上谈兵的笔试有点八股,ACM般的机试时间又太紧,面对面的聊天或者刺刀见红般的白板写代码算是比较好的了解一个人技术水平的手段,但是这三种方式的考核方式其实都和真实的工作流程相左;而这种rush类型的题目基本上可以反应一个人工作能力——你可以利用google、可以去查算法书籍、可以在有限的时间内再去学习一些技术,唯一要求的就是诚信。
我看到此题的第一想法就是暴力试探法,因为对于knight p(x, y)而言,p(x-1,y), p(x+1, y), p(x, y-1), p(x, y+1)四个方向上相邻的点都是可达的。按此思路只需要“步步为营,稳扎稳打”就可以到达“胜利的终点”p(N, N)。
显然,这种策略不是对方想要的结果。适逢夜深燥热、大脑混沌,且先睡去,待次日云淡风清,再做打算。果不其然,早起在“响应大自然呼唤”的时候,我想到了理论上的最佳解决方案,不但能给出一条可行的路径,而且这条路径保证是最短的。聪明的你或许已经想到,没错,这个题目本质上就是一道unweighted undirected shortest path的图论问题。转换的方法很简单:从左到右从上到下,将(N*N)的棋盘上N*N个point顺次编号为0, 1, … N*N-1,对于棋盘上的一个点p(x, y),按照knight的走法,其下一步到达的点最多有8个:p1(x-1, y-2), p2(x-1, y+2), p3(x+1, y-2), p4(x+1, y+2), p5(x-2, y-1), p6(x-2, y+1), p7(x+2, y-1), p8(x+2, y+1),所有这些点的集合构成了点p在unweighted undirected graph中的邻接表。接下来BFS算一下最短路径(由于是无权图,因此还是不劳烦Dijkstra大侠的高招了,简单的BFS就够了),再做一些简单的输入输出和错误处理就OK啦。那么最后的一块骨头就是Coding了。
我最后大概花了15个小时左右完成了C++/Lisp/Python三种不同语言的程序,三者的Coding时间比大概是5:2:3,这也是我第一次用不同的语言来写同样的程序,原本想起来不算太难的工作,写完后还是很有收获的2,勿在浮沙筑高台,Coding这种工匠手艺活,眼高手低是最要不得的。
文既至此,我就顺便谈谈语言学习的问题,高贤见笑后,如有时间,万望不吝赐教。
3 C++
按照我所了解的当代中国本科计算机教育,大多人工科学生学习的第一门编程语言应该是C,接下来如果还有需要的话,就是C++或者Java了。不幸的是,鄙人也是这样过来的,幸运的是,鄙人天资愚鲁,学了半年C++后知难而退,转战了实战主义的Shell Script和Python,这一年来闹中取静,为了探寻MapReduce算法模型的本原,啃了几本Lisp的书,回过头来,总算对C++的诸多繁杂特性有了一些全局性的认识,这种认识来自于跨语言的佐证和思考,而非来自于C++语言本身。事实上C++中的很多概念在C++中是无法学到通透的,比如:
- C++11的lambda:你可以不知道Alonzo Church, 也可以不会Lambda calculus3, 但是如果你不知道什么叫Higher-order function4的话,你怎么好意思说,你会lambda?lambda仅仅是匿名函数那么简单吗?匿名函数有何用?匿名函数的递归问题怎么解决5?STL里的functor究竟是语言机制设计的经典还是为了弥补语言不足所贴的狗屁膏药?
-
STL:STL几乎就是C++经典库和设计的代名词,通过迭代器将算法和组件分离6,力求达到性能和代码重用的双重顶点。
- 可惜你不知道的是,迭代器并不是一个高层次的抽象机制,迭代器的本质是一种迭代遍历操作,至于通过什么手段来迭代遍历,这些本不应该是使用者所应该关心的细节问题。所以对于下面的这段c++伪代码:
for (vector<int>::iterator itr = v.begin(); itr != v.end(); ++itr)
{
do_something(*itr)
}
-
- 其高阶抽象代码应该是:
for_each(v, do_something)
-
- 稍微了解一点Lisp的读者都能想到如下的等价伪代码7:
(mapcar #'do_something v)
-
- 每次你写"v.begin(), v.end()"这样的代码时,你就不知不觉地降低了自己的抽象层次,使自己脱离问题域而转向去纠结于实现域,不要小看这种力量, 软件工程的一切欢乐和痛苦,只是聚沙成塔的两个极端而已。
- 事实上STL本身包含很多函数式编程的思想,比如说 functor这种组件,其实质是将在c++中作为second-class的函数通过类封装的手段提升至first-class,如此一来,函数的核心操作摇身一变成为functor的时候,就可以像函数式语言里面的Higher-order function一样,可以用类成员变量来模拟实现闭包,可以被当做普通参数传递返回(这样就不用费力去写令很多新手语法不过关的函数指针了),甚至可以通过std::bind1st/std::bind2nd这种奇技淫巧实现一个蹩脚的线性代数级别的函数映射与变换。8
- STL里面大量的算法都是基于迭代器的抽象而进行序列的批量化操作,同种算法多种容器的核心技术是 基于C++模板实现的静多态 ,"It is better to have 100 functions operate on one data structure than 10 functions on 10 data structures",从这个角度上来讲,STL算法和Lisp中针对sequence类型数据的各种函数(mapcar/remove/remove_if/member等)有异曲同工之妙。
- 最后来八一八STL之父Alexander Stepanov,其实人家是莫斯科大学数学系毕业的高材生,所以STL背后有着很深的数学思想,"Elements of Programming"或许是解开这个谜题的钥匙。另外,Alexander是反对OOP的。
-
泛型与模板:这大概是Modern C++中最重口味的话题了,也是很多C++初学者的噩梦。我认为C++模板足够强大,但同时也足够扭曲且非人道,布满了大大小小的地雷和陷阱。探究起来,C++模板之所以有那么多坑,其历史原因在于C++模板是一种被发现而非被发明的技术9。C++最初引入模板的动机非常简单,无非就是写一些通用的min/max函数和一些简单的泛型类,但是人们后来发现C++模板竟然是图灵完备的,这件事极大的刺激了C++程序员的神经,于是乎,一个又一个神乎其技的ad hoc的模板编程的奇技淫巧被挖掘出来,这些奇技淫巧分布在C++标准库的各个角落,而这些奇技淫巧本身也成了许多C++程序员绕不开躲不过的必修课。C++的学习就像练剑一样,练到一定境界总会碰到这样那样的瓶颈,这个时候很多人就会认为自己功力不够,或者是练得不够刻苦,于是乎找来一本又一本的“武功秘籍”10更加刻苦地练剑。殊不知,如果方向不对,再怎么努力刻苦也难免事倍功半。你可知道,繁杂的C++模板特性的背后,其本质到底是什么?
-
C++模板的本质在于用编程的手段显式地控制编译器的代码生成。没错,聪明的你已经想到,Lisp的macro做的也是同样的事情。但是不同于Lisp的macro,由于C++模板的先天不足和C++静态类型系统的限制,C++在语言层面上对模板编程的支持非常有限。荣耀先生有一篇非常精炼的PPT《C++模板元编程技术与应用》, 基本上概括了C++模板编程的核心机制和语言实现,我摘录了一些如下:
- 模板元编程使用静态C++语言成分,编程风格类似于函数式编程,其中不可以使用变量、赋值语句和迭代结构等。
- 在模板元编程中,主要操作整型(包括布尔类型、字符类型、整数类型)常量和类型。被操纵的实体也称为元数据(Metadata)。所有元数据均可作为模板参数。
- 由于在模板元编程中不可以使用变量,我们只能使用typedef名字和整型常量。它们分别采用一个类型和整数值进行初始化,之后不能再赋予新的类型或数值。如果需要新的类型或数值,必须引入新的typedef名字或常量。
-
编译期赋值通过整型常量初始化和typedef语句实现。例如:
- enum { Result = Fib<N-1>::Result + Fib<N-2>::Result};
- static const int Result = Fib<N-1>::Result + Fib<N-2>::Result;
-
成员类型则通过typedef引入,例如:
- typedef T1 Result;
- 条件结构采用模板特化或条件操作符实现。如果需要从两个或更多种类型中选其一,可以使用模板特化,如前述的IfThenElse11。
- 静态C++代码使用递归而不是循环语句。递归的终结采用模板特化实现。如果没有充当终结条件的特化版,编译器将一直实例化下去,一直到达编译器的极限12。
- 而正是由于底层支撑性语言机制的匮乏,使得C++模板编程非常的冗长、丑陋,甚至有些扭曲乃至非人道13。我以为,用一门连IfThenElse都要靠Hack去实现的子语言去写高阶代码,和用汇编语言去写高级数据结构是差不多的。所以你去看STL的代码,看std::binary_function,你会发现大量的typedef做类型推导。可是你想过没有,类型推导真的是必须的吗?未必。这么多typedef完全是拜C++的静态类型系统所赐。我不是说静态类型不好,事实上关于静态类型和动态类型历来都是学术界和工业界乐此不疲的热门口水战。我想说明的是, 有时候你想要舞蹈的时候,要低头看看,你的脚上是否带着不必要的镣铐。 C++的静态类型系统对于泛型编程而言,就是这样的镣铐。
-
C++模板的本质在于用编程的手段显式地控制编译器的代码生成。没错,聪明的你已经想到,Lisp的macro做的也是同样的事情。但是不同于Lisp的macro,由于C++模板的先天不足和C++静态类型系统的限制,C++在语言层面上对模板编程的支持非常有限。荣耀先生有一篇非常精炼的PPT《C++模板元编程技术与应用》, 基本上概括了C++模板编程的核心机制和语言实现,我摘录了一些如下:
- 引用、指针、const、static等:除了以上比较“重口味”的C++语言特性,C++里还有各种各样的语言小尾巴,而且这个尾巴一般都拉的特别长。当然,尾巴长的好处之一就是可以养活很多语言专家,什么effective啊、exceptional啊、faq啊啥的,在所有的编程语言中,C++这点绝对是独树一帜。其实每个语言特性的背后都有值得深究的知识, 没有任何事情是想当然的。14 const够简单了吧?可是你知道const pointer和pointer to const的区别吗?你知道什么时候用const引用传参什么时候返回const引用什么时候返回值吗?你知道const成员函数吗?你知道为什么会有初始化成员列表的存在吗?再来说说引用这个概念,其本质上就是一种受限指针加上编译器层面上的语法糖修饰,按理说不太难,但是什么时候传引用返回引用确是值得深究的好问题,搞清楚了这点,你就会搞明白C++中的copy constructor/copy assignment operator,Java中的Object.clone(),Python中的"is"、和Lisp中的eq/eql/equal。传引用/指针还是传值涉及到深刻的程序语言原理,并不是你想象的那么简单而已。
- 以上谈了这么多,读者可能会问,既然C++如此繁杂,还要不要学习C++?学,当然要学,否则你怎么批判呢?怎么学?批判地学。要去学习语言机制的根源和本质而不要迷失在语言特性的森林里15。
- 最后,还是回到面试题上,还是放上鄙人的C++代码,也好和Lisp/Python版的程序做一个小对比:
#include <queue>
#include <limits>
#include <iostream>
#include <vector>
#include <map>
#include <functional>
#include <queue>
#include <list>
#include <cstdlib>
using namespace std;
struct vertex
{
int index; /// the vertex index, also the vertex name
vertex* prev; /// the prev vertex node computed by bfs and bfs_shortest
int dist; /// the distance to the start computed by bfs
/// and bfs_shortest
vector<vertex*> adj; /// the adjacency list for this vertex
vertex(int idx)
: index(idx) {
reset();
}
void reset() {
prev = NULL;
dist = numeric_limits<int>::max();
}
};
class graph
{
public:
graph() { }
~graph();
void add_edge(int start, int end);
void bfs(int start);
void bfs_shortest(int start);
list<int> get_path(int end) const;
void print_graph() const;
protected:
vertex* get_vertex(int idx);
void reset_all();
list<int> get_path(const vertex &end) const;
private:
/// disable copy
graph(const graph &rhs);
graph& operator=(const graph &rhs);
typedef map<int, vertex*, less<int> > vmap;
vmap vm;
};
graph::~graph() {
for (vmap::iterator itr = vm.begin(); itr != vm.end(); ++itr)
{
delete (*itr).second;
}
}
/**
* return a new vertex if not exists, else return the old vertex, using std::map
* for vertex management
*
* @param idx vertex index
*
* @return a (new) vertex of index idx
*/
vertex* graph::get_vertex(int idx) {
/// cout << "idx: " << idx << "\tvm.size(): " << vm.size() << endl;
vmap::iterator itr = vm.find(idx);
if (itr == vm.end())
{
vm[idx] = new vertex(idx);
return vm[idx];
}
return itr->second;
}
/**
* clear all vertex state flags
*
*/
void graph::reset_all() {
for (vmap::iterator itr = vm.begin(); itr != vm.end(); ++itr)
{
(*itr).second->reset();
}
}
/**
* add an edge(start --> end) to the graph
*
* @param start
* @param end
*/
void graph::add_edge(int start, int end) {
vertex *s = get_vertex(start);
vertex *e = get_vertex(end);
s->adj.push_back(e);
}
/**
* print the graph vertex by vertex(with adj list)
*
*/
void graph::print_graph() const {
for (vmap::const_iterator itr = vm.begin(); itr != vm.end(); ++itr)
{
cout << itr->first << ": ";
for (vector<vertex*>::const_iterator vitr = itr->second->adj.begin();
vitr != itr->second->adj.end();
++vitr)
{
cout << (*vitr)->index << " ";
}
cout << endl;
}
}
/**
* traversal the graph breadth-first
*
* @param start the starting point of the bfs traversal
*/
void graph::bfs(int start) {
if (vm.find(start) == vm.end())
{
cerr << "graph::bfs(): invalid point index " << start << endl;
return;
}
vertex *s = vm[start];
queue<vertex*> q;
q.push(s);
s->dist = -1;
while (!q.empty()) {
vertex *v = q.front();
cout << v->index << " ";
q.pop();
for (int i = 0; i < v->adj.size(); ++i)
{
if (v->adj[i]->dist != -1)
{
q.push(v->adj[i]);
v->adj[i]->dist = -1;
}
}
}
}
/**
* the unweighted shortest path algorithm, using a std::queue instead of
* priority_queue(which is used in dijkstra's algorithm)
*
* @param start
*/
void graph::bfs_shortest(int start) {
if (vm.find(start) == vm.end())
{
cerr << "graph::bfs_shortest(): invalid point index " << start << endl;
return;
}
vertex *s = vm[start];
queue<vertex*> q;
q.push(s);
s->dist = 0;
while (!q.empty()) {
vertex *v = q.front();
q.pop();
for (int i = 0; i < v->adj.size(); ++i)
{
vertex *w = v->adj[i];
if (w->dist == numeric_limits<int>::max())
{
w->dist = v->dist + 1;
w->prev = v;
q.push(w);
}
}
}
}
/**
* get the path from start to end
*
* @param end
*
* @return a list of vertex which denotes the shortest path
*/
list<int> graph::get_path(int end) const {
vmap::const_iterator itr = vm.find(end);
if (itr == vm.end())
{
cerr << "graph::get_path(): invalid point index " << end << endl;
return list<int>();
}
const vertex &w = *(*itr).second;
if (w.dist == numeric_limits<int>::max())
{
cout << "vertex " << w.index << " is not reachable";
return list<int>();
}
else {
return get_path(w);
}
}
/**
* the internal helper function for the public get_path function
*
* @param end
*
* @return a list of vertex index
*/
list<int> graph::get_path(const vertex &end) const {
list<int> l;
const vertex *v = &end;
while (v != NULL) {
l.push_front(v->index);
v = v->prev;
}
return l;
}
class chessboard {
private:
struct point {
int x;
int y;
point(int px, int pb)
: x(px), y(pb) { }
};
public:
chessboard(int s);
void solve_knight(int x, int y);
protected:
bool is_valid(const point &p);
point next_point(const point &p, int i);
private:
graph board;
int size;
};
/**
* constructor, build a underlying graph from a chessboard of size s
*
* @param s
*/
chessboard::chessboard(int s)
: size(s) {
for (int i = 0; i < size; ++i)
{
for (int j = 0; j < size; ++j)
{
int start = i * size + j;
point p(i, j);
for (int k = 0; k < 8; ++k)
{
/// the next possible knight position
point np = next_point(p, k);
if (is_valid(np))
{
int end = np.x * size + np.y;
/// add edges in both directions
board.add_edge(start, end);
board.add_edge(end, start);
}
}
}
}
}
/**
* find and print a path from (x, y) to (size, size)
*
* @param x
* @param y
*/
void chessboard::solve_knight(int x, int y) {
int start = (x-1) * size + (y-1);
int end = size * size - 1;
board.bfs_shortest(start);
list<int> l = board.get_path(end);
int count = 0;
for (list<int>::const_iterator itr = l.begin(); itr != l.end(); ++itr)
{
cout << "(" << *itr/size + 1 << ", " << *itr%size + 1<< ")";
if (count++ != l.size() - 1)
{
cout << " -> ";
}
}
cout << endl;
}
/**
* whether or not the point is valid in the chessboard
*
* @param p
*
* @return true for valid
*/
bool chessboard::is_valid(const point &p) {
if (p.x < 0 || p.x >= size - 1 || p.y < 0 || p.y >= size - 1)
{
return false;
}
return true;
}
/**
* the next possible position, every has 8 next possible position, though not
* all 8 position is valid
*
* @param p the original knight position
* @param i
*
* @return
*/
chessboard::point chessboard::next_point(const point &p, int i) {
int knight[8][2] = {
{2, 1}, {2, -1},
{-2, 1}, {-2, -1},
{1, 2}, {1, -2},
{-1, 2}, {-1, -2}
};
return point(p.x + knight[i][0], p.y + knight[i][1]);
}
int main(int argc, char *argv[])
{
if (argc != 4)
{
cerr << "Wrong arguments! Usage: knight.bin N x y" << endl;
return -1;
}
int N = atoi(argv[1]);
int x = atoi(argv[2]);
int y = atoi(argv[3]);
chessboard chess(N);
chess.solve_knight(x, y);
return 0;
}
4 Lisp
Lisp是一门阳春白雪的语言,前两天我去面试一个linux后端开发的职位,面试官看到我的简历还当面问我“Lisp是一个什么东西”……Lisp最广为人知的特点,大概就是——括号了吧。因此Lisp除了代表"List Processing", 还有一个别名"Lots of Irritating Superfluous Parentheses"。括号的背后其实是S-expression。诈看上去,S-expression (+ 1 2)比之于我们熟悉的"1 + 2"确实要晦涩一点,但是你要明白的是,我们之所以比较喜欢"1 + 2"这种形式的写法,那完全是我们小学教育的错16。想想高等数学吧,函数f(x, y, z),翻译成Lisp的S-expression就是(f x y z),但是如何翻译成"1 + 2"形式的语句呢?事实上在Lisp发明之初,确实有人指出说S-expression写起来特别的别扭,John McCarthy也曾经试图将S-expression转换成M-expression 的形式,可是后来人们发现S-expression所带来的好处远远超出其微末的学习成本,M-expression的计划也就无疾而终了。S-expression是Lisp程序员一切欢乐与痛苦的来源17。
- S-expression带给Lisp的第一个好处是语法的简单一致性。显而易见的例子就是Lisp中没有类似于C语言中的运算符优先表。
- S-expression带给Lisp的第二个好处是Homoiconicity, 体现在Lisp中,就是"code is data"18。
-
基于"code is data", S-expreesion带给Lisp的第三个好处就是强大的macro。前面我们曾经讲到,“C++模板的本质在于用编程的手段显式地控制编译器的代码生成“,也就是所谓的元编程meta-programming。 我们还提到,C++在语言层面上对meta-programming的支持非常匮乏,因此才会有各种各样的workarounds(effective/exceptional中称为idioms或者techniques)。与C++模板不同,Lisp的macro可以调用几乎所有Lisp的语言机制。正式由于S-expression的存在,使得Lisp代码本身不经解析就是一颗完美的对编译器极度友好的抽象语法树, 当我们写Lisp macro的时候,我们其实是在和Lisp编译器交谈 ,我们告诉Lisp编译器,那些参数需要求值19,那些代码需要循环执行(do/dolist/dotimes),那些结构需要定义getter/setter(defstruct)等等。要知道,Lisp的老本行就是List Processing,而任何合法的Lisp的代码本身也一个List,用Lisp的能力来操作自身的代码,进行代码变换,这就是Lisp的macro。
- 好学的读者可能会问,元编程到底有什么用?其实很简单,当你在写一句句C语言代码的时候,你就已经在用元编程了。广义上来讲,任何能够控制代码生成的编程方法都可以看作是元编程,元编程其实是编译器的主要工作职能。不明白?好吧。我们要从遥远的汇编时代讲起。没有C语言(高级语言)之前,人们在汇编语言的酱缸中浸淫。终于有一天,有那么几位智者大神跳出来,总结出说编程语言的控制结构无非就是顺序/选择/循环三种,于是就有了if,有了for/while,从此程序员就快乐写写if/for,抛弃了汇编,因为有一个叫做编译器的助手可以自动生成if/for的底层汇编代码。如果说编程是为了解决重复性的工作,那么元编程就是为了解决重复性的编程代码工作。
- Lisp的macro所带来的元编程能力与其他语言相比,其最大的特点在于Lisp的macro元编程是可扩展的,也就是说,我们可以通过Lisp的macro写一些库,而这些库和语言本身的机制能够很好的融合在一起;其余的语言诸如C++/Java,其语言机制的扩展则需要进行漫长的标准化进程。
除了以上,Lisp还有一些非常独特的优点,使得这么古老的阳春白雪般的语言虽然尚未蓬勃,但注定不会消亡:
- 快速反馈的交互式开发模型。是的,谈到Lisp开发就不能不谈到Emacs+Slime这套革命性的开发环境,没有Slime的Lisp,就像没有武器的战士一样。不同于C++的先构建再运行的开发模型,Lisp的开发模型是交互式的。你写了一个defun一个defstruct,不需要去main函数中写一段测试代码和print语句,然后编译运行看看结果是否符合预期;在Slime+Lisp的开发环境中,写了一个defun,C-c C-c即可编译完成,C-x C-e即可执行当前的一个表达式,快速的反馈和修改能够最大程度上保证你思维的连续性。关于这点可以参考我写的走进Lisp的世界——兼谈Emacs下Lisp的开发环境(上)。
-
强烈的数学味,更高层次的抽象,专注于what而不是how。
- Paul Graham在The Roots of Lisp中写到"It's worth understanding what McCarthy discovered, not just as a landmark in the history of computers, but as a model for what programming is tending to become in our own time. It seems to me that there have been two really clean, consistent models of programming so far: the C model and the Lisp model. These two seem points of high ground, with swampy lowlands between them. As computers have grown more powerful, the new languages being developed have been moving steadily toward the Lisp model. A popular recipe for new programming languages in the past 20 years has been to take the C model of computing and add to it, piecemeal, parts taken from the Lisp model, like runtime typing and garbage collection."
- 按照我的理解,我们可以对中文“计算机”这个词语做一次咬文嚼字的分拆,Lisp代表着“计算”,而C语言则代表“机”。
- Lisp具有强烈的数学色彩,Lisp程序中大量使用递归,深刻理解递归几乎是Lisp程序员的必备生存技能20。而C语言则终点关注底层机器模型,short/int/long/long long,不同数据类型的区分,榨干机器的内存空间;大量使用指针,将完整的冯诺依曼机器模型暴露给程序员,榨干机器的整体性能。
-
在Lisp中更加强调what you want,而C中则更加倾向于给出长长的算法步骤和状态变换指令,专注于how to get it。
- 比如求一个list的长度,在Lisp中,其核心代码就是(+ 1 (lenght (cdr lst)));而在C中,恐怕要设置int i = 0和各种计数器了21。
-
强类型的动态语言,一致的语法规则,关注实现域而非问题域,摒弃编程中的心智包袱。
- C++是一门有心智包袱的语言22,在C++编程中,我们常常要考虑诸如是传值还是传引用、要不要进行运算符重载、深拷贝还是浅拷贝、堆内存还是栈内存等等这些实现域而非问题域的语言细节问题。我不是说关注实现域这点不好,只是不能太过,而C++的讨厌之处就在于,为了所谓一点点的性能提升,经常性地将苦命的码农们从问题域拉回实现域。
-
万能的List,快速的原型构建能力。
- 如何用可递归的List来一体化的表达常见的数据结构,这个问题比较深刻,后续我会再写一篇文章深入探讨下。
本节的最后,还是给出完整的Lisp程序,核心代码只有70行左右,大概是C++的三分之一左右。主题算法和代码来自于《ANSI Common Lisp》3.15节。顺带广告,《ANSI Common Lisp》是非常不错的Common Lisp书籍(用来入门的话还是比较难啃的),300页不到的篇幅里基本上覆盖了Common Lisp大部分的语言特性,并且有很多极具实用价值的小程序(最短路、行程压缩编码、二叉树、二分搜索、光线跟踪算法等等)。我认为此书之于Lisp,相当于K&R C之于C。
(defun point2index (x y n)
"convert a coordinate point to an index"
(+ (* x n) y))
(defun index2chess (index n)
"convert an index back to a coordinate point"
(floor index n))
(defun build-graph (n)
"build a undirected unweighted graph according to the chess rules about
knight"
;; use lisp array to keep the vertex map
(let ((vm (make-array (* n n) :initial-element nil)))
;;; define some auxiliary function
(defun is-valid (x y)
"whether or not the point is valid in the chess board"
(and (>= x 0) (< x n)
(>= y 0) (< y n)))
(defun all-adj-points (x y)
"build the adjacency list for point (x, y)"
(let ((adj-list))
;; return every possible next knight position as a list
(dolist (next-step
'((2 . -1) (2 . 1)
(-2 . -1) (-2 . 1)
(1 . -2) (1 . 2)
(-1 . -2) (-1 . 2)))
(let ((nx (+ x (car next-step)))
(ny (+ y (cdr next-step))))
(if (is-valid nx ny)
;; build the adjacency list
(push (point2index nx ny n) adj-list))))
adj-list))
(dotimes (i n)
(dotimes (j n)
(setf (aref vm (point2index i j n)) (all-adj-points i j))))
vm))
(defun shortest-path (start end graph)
"one-source unweighted shortest-path algorithm using bfs method"
(bfs end (list (list start)) graph))
(defun bfs (end queue graph)
"the internal bfs routine to find shortest path"
(if (null queue)
nil
(let* ((path (car queue))
(node (car path)))
(if (eql node end)
(reverse path)
(bfs end
;; pop the queue and push some new path into the queue
(append (cdr queue)
(new-paths path node graph))
graph)))))
(defun new-paths (path node graph)
"return the new-paths according to the node's adj list"
(mapcar #'(lambda (n)
(cons n path))
(cdr (aref graph node))))
(defun solve-knight (n x y)
"the main function to solve knight problem"
(let ((path (shortest-path (point2index (- x 1) (- y 1) n)
(point2index (- n 1) (- n 1) n)
(build-graph n))))
;; print the start point first
(multiple-value-bind (x1 y1)
(index2point (car path) n)
(format t "(~A, ~A)" (+ x1 1) (+ y1 1)))
;; print the path
(mapcar #'(lambda (obj)
(multiple-value-bind (px py)
(index2point obj n)
(format t " -> (~A, ~A)"
(+ px 1)
(+ py 1))))
(cdr path))
;; return the path
path))
;;; some test
;; CL-USER> (SOLVE-KNIGHT 6 1 1)
;; (1, 1) -> (3, 2) -> (4, 4) -> (5, 6) -> (6, 4) -> (4, 5) -> (6, 6)
;; (0 13 21 29 33 22 35)
;; CL-USER> (SOLVE-KNIGHT 8 1 1)
;; (1, 1) -> (3, 2) -> (4, 4) -> (5, 6) -> (6, 8) -> (7, 6) -> (8, 8)
;; (0 17 27 37 47 53 63)
;; CL-USER> (SOLVE-KNIGHT 8 2 1)
;; (2, 1) -> (3, 3) -> (4, 5) -> (5, 7) -> (7, 6) -> (8, 8)
;; (8 18 28 38 53 63)
5 Python
坦白地说,我对Python的了解远不如C/C++,甚至不如Lisp,尽管我也用Python写过一些不大不小的原型程序,但是这些程序都没有触及到Python的语言核心。前两天写这个knight rush的程序,还要去翻书,熟悉下Python OOP编程的一些知识。我以为,Python是一门实用主义至上的语言,在保证实用主义的前提下,Python从诸多语言中吸收了很多特性,并一一做了精简(Python的OOP甚至没有private,而Python lambda对比Lisp算很一般),再加上简单至上的文化和缩进式的代码风格,构成了当今Python语言的主要面貌。
即便如此,我认为Python还是值得学习的。它既不像C/C++那样令人紧张、也不像Lisp那样阳春白雪,对比Shell Script,Python有自己的内建数据结构,能够在很大程度上替换Shell Script。其实和Python同级的语言还是有很多的,比如Perl,Ruby。Ruby我不了解,但是我对Perl/PHP/Shell这类遍布'$'符号的语言一向没什么好感,因为这类语言的可读性一般都很差。
其实关于Python本身,我已经没有太多想法可写,可能一方面我对Python的了解实在算不上深入,另一方面,Python本身也是不希望它的使用者过多关注于语言本身吧。对于Python,简单了解后拿过来直接用就好了,什么代码风格、缩进啊,那都是过去时的事情了。
作为对比,还是贴出Python版的Knight rush程序:
#!/usr/bin/env python2
import sys
class graph(object):
"""unweighted directed graph
"""
def __init__(self):
"""set _vmap to and _vprev an empty python dict
all vertex are represented by a simple index
_vmap: {vertex x: x's adjacency list}
_vprev: {vertex x: x's prev vertex computed by bfs routine}
"""
self._vmap = {};
self._vprev = {};
def add_edge(self, start, end):
"""add an edge to the graph
"""
if self._vmap.has_key(start):
self._vmap[start].append(end)
else:
self._vmap[start] = [end]
def bfs_shortest(self, start):
"""one-source shortest-path algorithm
"""
queue = [start]
self._vprev[start] = None
while len(queue) != 0:
v = queue[0]
queue.pop(0)
if self._vmap.has_key(v):
v_adj = self._vmap[v]
else:
continue
for nextv in v_adj:
if self._vprev.has_key(nextv):# and self._vprev[nextv] is not None:
# nextv has already found its parent""
continue
else:
queue.append(nextv)
self._vprev[nextv] = v
def get_path(self, end):
"""return the shortest path as a python list
"""
v = end;
path = []
while self._vprev.has_key(v) and self._vprev[v] is not None:
path.insert(0, v)
v = self._vprev[v]
if self._vprev.has_key(v):
path.insert(0, v) # insert the start point to the path
else:
print "destination %d is not exist or unreachable" % v
return path
class chessboard(object):
"""a chessboard of size n*n class
"""
def __init__(self, n):
"""build the internal graph representation of the chessboard
Arguments:
- `n`: size of the chessboard
"""
self._size = n
self._board = graph()
next_point = ((2, 1), (2, -1), \
(1, 2), (1, -2), \
(-2, 1), (-2, -1), \
(-1, 2), (-1, -2))
for x in range(n):
for y in range(n):
start = self.point2index(x, y)
for dx, dy in next_point:
nx = x + dx
ny = y + dy
if self.is_valid(nx, ny):
end = self.point2index(nx, ny)
self._board.add_edge(start, end)
def is_valid(self, x, y):
"""whether or not point (x, y) is valid in the chessboard
"""
return 0 <= x < self._size and 0 <= y < self._size
def point2index(self, x, y):
"""convert a chessboard point to the internal graph vertex index
"""
return x * self._size + y
def index2point(self, p):
"""convert the internal graph vertex index back to a chessboard point
"""
return (p / self._size, p % self._size)
def solve_knight(self, x, y):
"""just solve it
"""
start = self.point2index(x, y)
end = self.point2index(self._size - 1, self._size - 1)
self._board.bfs_shortest(start)
path = [self.index2point(x) for x in self._board.get_path(end)]
return [(x + 1, y + 1) for x, y in path]
def main():
"""main routine
"""
# g = graph()
# g.add_edge(1, 2)
# g.add_edge(1, 3)
# g.add_edge(2, 3)
# g.add_edge(3, 4)
# g.bfs_shortest(1)
# print g.get_path(4)
if len(sys.argv) != 4:
print """Wrong arguments! Usage: ./knight.py N x y
"""
return -1
N = int(sys.argv[1])
x = int(sys.argv[2])
y = int(sys.argv[3])
chess = chessboard(N)
print chess.solve_knight(x - 1, y - 1)
return 0
if __name__ == "__main__":
main()
# some test data
# $ ./knight.py 6 2 2
# [(2, 2), (4, 3), (6, 4), (4, 5), (6, 6)]
# $ ./knight.py 6 2 2
# [(2, 2), (4, 3), (6, 4), (4, 5), (6, 6)]
# $ ./knight.py 4 2 2
# [(2, 2), (4, 3), (2, 4), (3, 2), (4, 4)]
# $ ./knight.py 4 1 1
# [(1, 1), (3, 2), (4, 4)]
# $ ./knight.py 4 2 3
# [(2, 3), (4, 4)]
# $ ./knight.py 20 2 3
# [(2, 3), (4, 4), (6, 5), (8, 6), (10, 7), (12, 8), (14, 9), (16, 10), (18, 11), (20, 12), (19, 14), (20, 16), (19, 18), (20, 20)]
# $
6 总结
本文的初衷只是想针对此次面试做一个小的总结,但是写到一半发现面试题本身可写的内容不多,于是我就顺便写写我个人对C++/Lisp/Python的一些思考,而题目本身就“很悲剧地”成了本文的一个引子。写作终究不是一件容易的事情,将自己心中的想法转化成纸上清晰易懂的文字是一件耗时耗力的体力脑力并重的工作。整篇文章的写作大概耗时12个小时,但是写作的过程中也让我梳理了下自己的知识体系,如未鹏所言,“书写是为了更好的思考”。
罗嗦了这么多,其核心观点只有一个,那就是“ 要学会跳出语言的框架去学习语言 ”。站得高才能看得远, 只有跳出语言的框架,才能挣断语言给你的思维所上的枷锁,超越语言本身 ,看到更广阔的图景23。
–
Footnotes:
1 由于面试前后并没有保密协议,加上本文内容主要是以我个人的一些技术思考为主,因此题 目内容本引述邮件。如果违反相关招聘规定,请不吝告知,谢谢。
2 按照ACM的标准,我这样的编码速度估计是死定了。
3 其实我也不会,相信我,我只是在吹牛而已 ^_^ 。
4 四个程序员的一天, 一篇非常生动的高 阶函数科普小品文。
5 关于lambda函数的递归问题涉及到非常深刻的计算理论问题,其入门文章可以参考未鹏写的 康托尔、哥德尔、图灵——永恒的金色对角线, 围绕此话题有一本奇书 《哥德尔·艾舍尔·巴赫——集异璧之大成》, 曾长期绝版,最近当当有售,大家抓紧机会。
6 没错,STL和OO的数据封装思想几乎是背道而驰的。
7 Python中有Lisp Comprehension和类似于Lisp的map/reduce/filter套装。
8 boost function提供了更好的function object支持。
9 刘未鹏:泛型编程:源起、 实现与意义
10 关于C++语言特性的书籍简直可以用浩如烟海来形容,参看 这里、 这里。
11 关于这个IfThenElse模板,可以参考《C++ Templates》第15章的讲解与实现。
12 前文提到,C++模板代码是由C++编译器在编译期“解释执行”的,其冗长的编译时间、巨大的 编译资源以及内存资源需求,使得最新的GCC/Clang系列编译器对模板的递归层次支持也仅 有几千层而已。事实上编译时间的冗长也一直是C++模板被人诟病的地方之一。
13 看看《C++ Templates》Part 2吧,绝对 是顶级脑细胞杀手。
14 即便是int x = 3这样简单的一条赋值语句也不是你想象中的那么简单,看看 《SICP》 第三章吧。能够对变量直接赋 值是不同编程范式的一个主要区别,而这又从一个很重要的角度上决定了并行计算的本质困 难性。
15 怎么学?学习C++:实践者的 方法(Beta1)。
16 就好比我们喜欢十进制而非二进制,完全是因为上帝赐予了我们十根手指。
17 你也可以说,指针是C程序员一切欢乐与痛苦的来源。其实我想说的是,每种编程语言的核 心关注点不同,在此至上,语言本身会围绕着这个核心点发展出自己的一套设计哲学,然后 根据这套哲学来指导语言本身的设计和发展。
18 "Data is just dumb code, and code is just smart data",关于"code is data"的话题 涉及到计算机科学里面很多深刻的论题。比如说c程序中的.text段和.data段, 冯诺依曼体系结构和 哈佛体系结构, 编译器代码 生成等等。 Code is data, and it always has been。
19 学习Lisp带给你的一个思想革新就是,一个对象和这个对象的值是完全不同的东西(eval (quote x))。这是个很重要的概念,但这个概念在其余语言中往往是混为一体的,至少在语 法上是这样的。最简单的例子,比如c中的语句:x = x,等式的右边是x的值而不是x本身, 等式的左边是x本身而不是x的值,理解了这点,你就能理解C++中左值和右值的概念区别。 如果有机会,我会专门写篇文章,探讨下这个主题。
20 Lisp编程中的递归主要是数学归纳法的一种程式化转换, 《Common Lisp, A Gentle Introduction to Symbolic Computation》8.11节里面详细介绍了Lisp中递归的几种模式,清晰易懂, 强烈推荐。
21 这么简单的例子也许并不足以体现出Lisp和C这两种语言不同思维模式的区别,事实上如果 读者不去稍微深入地学习下Lisp的话,是很难体会到这种思维转变的。
22 具体可以参考孟岩先生的两篇文章, 用C设计,用C++编码 和 Linux之父话糙理不糙。
23 最后一个脚注(貌似我最近写文章脚注用得越来越多了,不知道这算是旁征博引还是逻辑不 清):侃侃那些美丽 的编程语言, ^_^ 。
永不停歇
2009年的最后一天的下午,和妞去外婆家吃了顿大餐,特别记得那里的青豆泥和黄金鸡翅,还有3块钱的麻辣豆腐。之后元旦的那几天陪妞泡图书馆,妞准备考研,我准备学期末的十几门考试。10号左右考研结束,我回到玉泉,硬着头皮编数值分析的8道题目。月中,漫长考试正式拉开序幕。月末28号早7点,起床看《计算理论基础》,10:30-12:30战斗在计算理论的战场上。然后接下来吃饭填饱肚子,回到寝室收拾行李。两点多出发,四点左右到机场,五点多飞机起飞,八点多到福州,摩的到车站,晚九点多坐上去厦门的大巴,午夜到厦门,饿得发昏,吃了一碗热汤面,夜里一点左右,找到旅馆就寝。
厦门几日参观了厦大,南普陀,在鼓浪屿上闲庭信步,听了一场很感动的吉他演奏。最后一晚特地到鼓浪屿上的小旅馆住了一宿。次日早起赶往车站,9点大巴到福州。半路大巴抛锚,磨蹭下午三点多才到福州。我和妞匆匆感到火车站。两分钟内交换整理了各自行李,妞独自踏上回家的动车——妞的手机坏了,我的手机充电器也丢了。半小时后我也上了回家的车,福州到北京,24小时的硬座。
回家几日,家里闹了点小矛盾,心情十分不好,才初九就提早跑了出来。和妞汇合,正是南方赏梅佳节。杭州植物园、余杭超山,留下了我们匆匆的脚步。而后心情还是不太舒畅,没怎么去上课,白天就在寝室睡大觉,晚上起来折腾Gentoo。实在心情不好就去夜爬宝石山,山顶的清灯古寺,躺在石椅上看看星星也好——虽然杭州的天空本就没有几颗星星。磨磨蹭蹭到3月底,被导师抓到实验室,开始了一个月的苦力生涯。现在想想那一个月的生活,还是挺好玩的。整个组就像个生产软件的小作坊——没有版本控制、没有QA和bug控制、需求总是不断在变、没有统一的代码风格、参差不齐的编码水平,致使项目一再延期。4月初妞去深圳实习,也不知道要多久。我一个人每天早晨从玉泉的最北边走到最南边,午夜在借着月色星光,听着自己的脚步声从最南边走回最北边。含笑开得正盛,晚上出实验室的时候就随手摘一多,清香醒脑,然后装在口袋里。满身的“香蕉味”。含笑,多么示意的一个名字啊。还有云南黄馨,一片片的黄,招蜂引蝶,很温暖。
这一个月仍然是没有去上过几节课。月末的编译原理无奈的放弃掉了,人工智能水了一篇科普文、仗着开卷考试混了过去。月底来了两个初中的朋友,twt和ww。我做东,吃吃喝喝,逛了几个我再熟悉不过的地方——西湖、紫金港等。4月30日下午3点分批赶往火车站,无奈交通大堵塞,退了火车票,大巴赶往上海,与南京来的朋友fx汇合。晚8点左右,南京路,四个初中的铁哥们,拥抱之后,非常不理智的加入了南京路上赶往黄浦江边去看世博会开幕烟火的汹涌人流——事实证明这绝对是个错误的决定。烟火没看到,倒见识到了恐怕这辈子再也不会见到的人口密度,真正的比肩接踵——竟然还有车子在人流里面慢慢的蹭,你说你这司机不是找抽嘛。
两日世博匆匆茫茫。想比较10月100万/天的人流规模,5.1三日20万/天的人流对我们来说已经算是很仁慈了。可是逛了一天我还是感到厌倦。第二天下午我就下定决心以后再也不凑这种热闹了。幸好2日晚上妞来上海,我就找了个理由告别了哥们,提前结束了原本预计三天的世博之旅。3号回到杭州。4号开始着手数模比赛。14号晚上霸占了实验室的小会议室,我主刀文档,ly和lyf负责数据和资料支持,三人通力合作,早9点拿出了最终的论文。结果也没有让我们失望,校赛二等奖,拿到了国赛的资格——虽然国赛铩羽而归。数模完了就开始很功利地刷ZOJ,开始还是很认真的在做,有一周周一早晨进入实验室一直待到周四中午才会,就在不停的刷ZOJ。后来时间上还是来不及,加上题目难度增大,就开始耍一些小花招,比如有些题目回去看别人的代码,然后看懂后自己照着写写就提交等等。最后在月底总算刷够了题目,好歹能去参加选拔赛见识一下了——虽然我承认这样的急功近利很不光彩。我们对人对事常常会有双重标准。比如我们痛恨关系人情,轮到自己的时候却拼了命的去找关系、攀人情;我们痛恨钱的万能,但是却希望自己能有更多的钱。对人对己,一视同仁,这个真的好难做到。
6月初就在补各种课写各种实验报告了。妞在家帮妹妹准备中考、学车、做毕业设计。妞的毕业设计做的也非常匆忙,答辩前还在画图,半夜开始做答辩PPT,早七点半哭哭啼啼的弄醒我,说PPT软件崩溃,夜里做的都没了。上午要第一个答辩。我就安慰着说别慌别慌,跟老师申请下调整下顺序。总算过了这一关。我自己花了半周左右的时间写完了初步的简历。13日我生日,腐败的抽出了半天的时间在九溪逛了逛,中午就感到zjg参加ACM新手上路第二场选拔,还是铩羽而归。15号左右开始找实习。20号左右ACM新手上路第三场选拔,错过旅行者年度散伙饭。选拔赛比完,心里明白,自己所谓的ACM梦想彻底告吹,专心找实习。25号拿下华数淘宝的offer。然后就是漫长的考试。煎熬的日子。恰好又赶上妞的外婆过世,虽然我非常希望妞在身边,但这也是无奈的事情。只有那实验室前的合欢,花如雪,飘落一地。一个人,实验室,软件工程、算法设计、J2EE、嵌入式系统、计算机体系结构实验、计算机组成实验,一门又一门的考试,疲于奔命的我。那个时候真的感觉自己再也不想上学不想考试了。每天心里就想着一个字——“熬”。考试之前完全看不下去,就在youku上看鲁豫有约了。现在想想那段日子实在太痛苦了。
7月12日,妞去上海正式上班,我也需要入职实习,好巧。早六点送妞去火车站,9点公交上睡到淘宝总部,被告知华数淘宝已经搬家。又是一路奔波,总算找对了地方。整个暑假还是一个人。一个人,九点上班,磨磨蹭蹭地八点四十五起床,三分钟洗脸刷牙,五十准点从寝室出发,五十五到古荡,九点坐上公交,四站,十分下车,十二到公司,十五开早会。午十二点聚餐、一点小憩、三点去领餐票、六点吃饭、磨磨蹭蹭六点半出门回玉泉,掏出古董的Nokia 6670,拍下傍晚的天空晚霞,或者路上赌成一排的车,彩信给妞——“妞,我回去啦”。八点到寝,开电脑,调好小音箱,音乐飘荡,书香四溢,一个人静静的享受。十点会给妞打个电话,午夜问声好梦晚安。说不上特别快乐,但是十分享受这样的日子。
9月开学,第一周周末数模国赛,弃赛,铩羽而归,蹭了三天的伙食。15日以后,一年一度的校园招聘正式拉开序幕。请了两次小假,都是中午到三点这样的时段,参加了一次百度的小型交流会,参加了一次有道选拔机试。中秋前几日也是事情不断。跟Ouka说好了要一起去楠溪江徒步三天,怎奈走之前三天胃痛非常,下午在校医院挂了盐水后还是很痛,晚上就直接打车到了省立同德继续挂了盐水,总算好了点。胃痉挛还是很痛苦的,胃镜也是,想想就发抖。Ouka担心还能否去徒步领队,我逞强说肯定没问题。挂完盐水后十一点回到yq,去参观生仪学院的某个实验室,谈到夜里一点,被硬发了一个直博的Offer……老妈在家乡听说我挂了盐水,掉了眼泪,给妞打了电话;妞在上海也怕的要死,兴夜匆匆赶来,午夜到了玉泉毛主席像,一个人等我到夜里一点。好在同德的药很管用。我见到妞的时候已经基本不痛了,反倒比折腾了一程的妞还生龙活虎,妞就说“怎么感觉是你应该照顾我而不是我赶来照顾你呢”。我就说“你难得照顾我一次嘛”。
次日早起回到寝室,千里连音,帮在北京的zhzf同志写简历,三个小时通力合作到中午,总算完成,然后哦zhzf就直接打印简历去面试了。过了几天告诉我被录取了,说是简历起了大作用了。下午去zjg借了一些睡袋和炉头,晚饭后打算打车到火车站,赶往上海。怎奈月到中秋,人们都忙着过节,交通堵塞,打的困难,等了将近一个小时竟然还是打不到车,报废了一张火车票。无奈只能大巴去上海。午夜到上海南站,打车回到住处已经夜里一点多了。次日早起背着两个大包赶往上海南站,我悲剧的没有带公交卡,排队买地铁票花了好长时间,离火车出发一分钟的时候我和妞赶到了检票口。已经迟了。于是Ouka和yy先行一步。我和妞改签至下一斑。下午三点四人终于在温州汇合。紧接着就赶往永兴。三日旅程诸多不顺。天气下雨,徒步溯溪水位暴涨,危险性大大增高;阴天,原本期望的银河也就此泡汤;第三天返程,乡野司机悲剧的开到了温州老站而非动车站,又一次导致火车晚点,四张票改签退票,损失200大洋;去长途站做大巴,只有去上海的大巴而没有去杭州的……于是我一个人被抛弃,仗着身上仅剩下的100元钱买了张到杭州的硬座票。妞比较顺利,晚上九点多就回到住处了;Ouka和yy身上没钱了,错过了若干班车,夜里四点才安全的回到寝室;我呢,铺上防潮垫在火车站大厅地上极其不雅观地睡了三个小时。然后硬座8个小时到杭州,下了火车就直接去上班去了……
9月30日晚上下班收拾东西赶上了回家的火车,一夜拥挤无座,到下午两点下车,到承德,到家,夜里11点了。待几日,9日返上海看妞,10日返杭,13-15日接待zyy和lyh,然后就是各种血淋淋的笔试面试。24日一夜无座到北京,26日百度开放日活动,然后上海->杭州->考试->上海->杭州->北京->承德->家->北京->百度。
一路匆忙,永不停歇。1月中旬的时候我就想:还有两周,挺过去就好了,挺过去咱就出去玩一圈;4月的时候心里想:再挺6个月,什么都能搞定了;8月的时候想:这个时候即使什么都不干也有一个很好的保底Offer了;9月数模三天想:算了就算了吧,时间来不及了;中秋徒步最担心的是:能不能安全准时地赶回去;10月的某日接到百度的面试通知:离下午面试还有七个小时,出去吃饭发呆上厕所还有五个小时,赶紧看书!11月回到杭州:老师,这数电你就给点面子让我过了吧;12月:坏了,今天忘记写日报了,明天得九点之前起床,赶到公司,补上周报………………
总是那么忙;总是闲不下来;总是不懂得拒绝;总是给把自己和别人的期望值抬的特别高。
可不可以睡一天的懒觉晒一天的太阳;可不可以看一天的电影而心里没有浪费时间的愧疚感和负罪感;可不可以逃离各种email、SNS、IM一个人静静地过过有期待有等待的日子;可不可以不要对自己要求那么高,做一个观众,观望看台下激烈的百米赛跑?
我们还是没有勇气,我们停不下来。我们一路匆忙、永不停歇。在这无尽的匆忙中追逐着自己的欲望,却离自己的理想一点点远去。
真的是这样吗?朝九晚五、绩效业绩、技术职称,这些就是我们人生的全部意义?为什么有时候我会很邪恶的以为人生有80%的意义产生在20%的假期里面呢?
说说接下来的计划吧。
-
学习:
- hadoop相关,重点看完O'Reilly的《Hadoop: The Definitive Guide : MapReduce for the Cloud》,写读书笔记。
- python,画一个学习脑图,总结下学习成果,重点研究下lxml、beautifulsoup、urllib模块。
- c#,完成一张脑图,总结下c#和java的不同,批判的学习,完成大程序作业。
- 软件架构,看看设计模式吧,过了考试。
- 运维相关,不断学习不断总结。
- CMS系统,调查下各种CMS系统,自己动手搭建一个,赶快给出一个小网站设计方案,拖了好久好久,太不应该了。
-
计划中:
- Qt,看完《C++ Programming with Qt 4》,计划好久的事情了。
- Lisp,看完《ANSI Common Lisp》,计划好久的事情了。
- 网络,看完《TCP/IP详解》一、三卷,计划好久的事情了。
- 数据库,看完《数据库系统实现》,自己动手实现一个miniSQL,计划好久的事情了。
- 摄影,看完《纽摄》,拍够十个卷,计划好久的事情了。
- 文艺,先搞定《温柔的夜》,再去攻坚《三毛全集》,计划好久的事情了。
- ……,计划好久的事情了。
-
毕业:
- 十门课
- 毕业设计
- 第二课堂
- 散伙饭
- 领到两证
- 看看能否再抽出三周出去骑两千公里。不过貌似很难有这个时间了。悲剧。
流水帐
4、5号从上海回来后,我自己的cpu就一直在以100%的负载在运行,每天平均睡不到7个小时,两周不到经历了各种事情,需要做个总结,否则下次再做总结恐怕写不下了。总结的风格依然是流水帐,技术加生活。
6号上班做了一个30+页的ppt,对自己两个月的实习成果做一个总结,系统描述了整个视频生产系统的设计、编程实现、工具使用细节等等,晚上部门会议做了报告,效果还不错。7、8两天写出了自己人生的第一个Python脚本,脚本的功能是分析nginx访问日志,提取用户信息,判断某个用户是否完整看完了某个视频等等,形象化一点,就是把类似于下面的log:
172.24.106.236 - - [01/Sep/2010:17:57:54 +0800] "-" 400 0 "-" "-" "-" 172.24.106.237 - - [01/Sep/2010:17:57:56 +0800] "-" 400 0 "-" "-" "-" 116.247.116.238 - - [01/Sep/2010:17:58:11 +0800] "GET /video/super_mpg_video/demo/taohua.f4v HTTP/1.1" 200 867480 "http://110.75.2.195/player/thvp/thVideoPlayer.swf?video=http://110.75.2.195/video/super_mpg_video/demo/taohua.f4v" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; Tablet PC 2.0)" "-" 172.24.106.236 - - [01/Sep/2010:17:58:24 +0800] "-" 400 0 "-" "-" "-" 172.24.106.237 - - [01/Sep/2010:17:58:26 +0800] "-" 400 0 "-" "-" "-" 116.247.116.238 - - [01/Sep/2010:17:58:53 +0800] "GET /video/super_mpg_video/demo/taohua.f4v HTTP/1.1" 200 2097152 "http://110.75.2.195/player/thvp/thVideoPlayer.swf?video=http://110.75.2.195/video/super_mpg_video/demo/taohua.f4v" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; Tablet PC 2.0)" "-" 172.24.106.236 - - [01/Sep/2010:17:58:55 +0800] "-" 400 0 "-" "-" "-" 172.24.106.237 - - [01/Sep/2010:17:58:56 +0800] "-" 400 0 "-" "-" "-" 172.24.106.236 - - [01/Sep/2010:17:59:25 +0800] "-" 400 0 "-" "-" "-" 172.24.106.237 - - [01/Sep/2010:17:59:26 +0800] "-" 400 0 "-" "-" "-" 172.24.106.236 - - [01/Sep/2010:17:59:55 +0800] "-" 400 0 "-" "-" "-" 172.24.106.237 - - [01/Sep/2010:17:59:56 +0800] "-" 400 0 "-" "-" "-" 172.24.106.236 - - [01/Sep/2010:18:00:25 +0800] "-" 400 0 "-" "-" "-" 172.24.106.237 - - [01/Sep/2010:18:00:26 +0800] "-" 400 0 "-" "-" "-" 59.42.126.48 - - [01/Sep/2010:18:00:51 +0800] "GET /video/super_mpg_video/20100826/moribingdu/moribingdu.f4v?th_key=4c7e3d82;1a7b6ebe;8292192f571cb7bbed3024e3998b5631&start=46582231&end=67158965 HTTP/1.1" 200 771638 "http://110.75.2.195/player/thvp/thVideoPlayer.swf?video=http://110.75.2.195/video/super_mpg_video/20100826/moribingdu/moribingdu.f4v&th_key=" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)" "-" 172.24.106.236 - - [01/Sep/2010:18:00:55 +0800] "-" 400 0 "-" "-" "-" 172.24.106.237 - - [01/Sep/2010:18:00:56 +0800] "-" 400 0 "-" "-" "-" 172.24.106.236 - - [01/Sep/2010:18:01:25 +0800] "-" 400 0 "-" "-" "-" 172.24.106.237 - - [01/Sep/2010:18:01:26 +0800] "-" 400 0 "-" "-" "-" 116.247.116.238 - - [01/Sep/2010:18:01:43 +0800] "GET /video/super_mpg_video/demo/taohua.f4v?start=20998492&end=41622742 HTTP/1.1" 200 20624263 "http://110.75.2.195/player/thvp/thVideoPlayer.swf?video=http://110.75.2.195/video/super_mpg_video/demo/taohua.f4v" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; Tablet PC 2.0)" "-" 172.24.106.236 - - [01/Sep/2010:18:01:55 +0800] "-" 400 0 "-" "-" "-" 172.24.106.237 - - [01/Sep/2010:18:01:56 +0800] "-" 400 0 "-" "-" "-"
转换成相应形象化的显示:
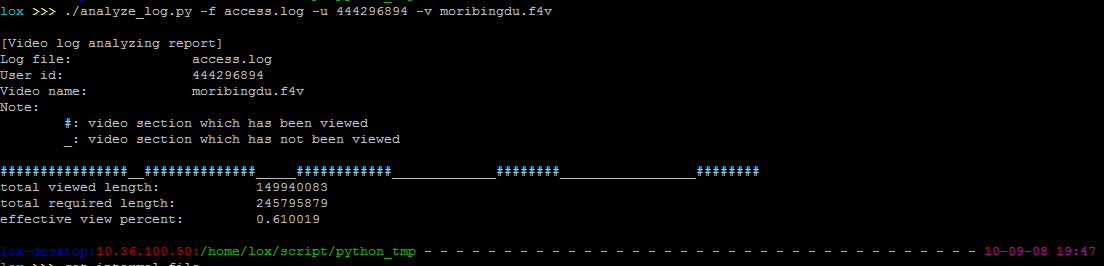
整个Python Script大概170多行,同时封装了几十行的Shell Script,算法是自己拍脑袋想出来的,具体描述可以另外写一篇技术文章了。脚本成形的过程渐渐体会到了Python的方便,结合了脚本语言的便捷性和高级语言的强大性,实乃居家旅行打家劫舍养家糊口之利器也。
9、10两天请假。9号睡了个小懒觉,然后去了趟校医院又开了一个星期的药,花掉100大洋左右,午饭后和同学会首,三人打车去西溪北园,准备CUMCM 2010。到了那边也没什么事情,下午3点半左右又走回玉泉,拿了实习记录本,去找导师签字。到了导师公司又等了半个小时,跟导师汇报下暑假实习的情况和自己要找工作的打算,简单谈了谈,骗了个90分回来。晚饭在西溪北园食堂吃的,饭后想到布袋也住在北园,约好去看她,巧的是碰到了哈哈、小包、破船一行,他们前脚刚要走,我后脚就跟过来了。由于布袋还要导尿,不太方便,我就一个人在北园里面转了几圈,买了个大西瓜和几桶泡面——西瓜给布袋,泡面是自己的。与布袋聊了有两个小时吧,听了她在千岛湖训练的很多故事,以及体制内运动员训练的一些内幕,加上他们从千岛湖逃窜的惊险一幕,走之前和布袋掰了手腕——当然我是不会输的,不过布袋的力气已经非常出色了,我敢说一般的男生不是她的对手;享受了阿姨自制的酸奶,一袋乳酸菌,放入保温瓶,自然发酵,有点西藏酸奶的味道,赞的。
11号早晨8点多拿到了CUMCM 2010的题目,A题是一道看似简单但非常复杂的几何计算题,B题就一句话——让你评估一下上海世博会的影响力。我倾向于选B题,因为看起来A题不太难——事实证明这个看起来不太难的结论是错误的,而且发挥余地有限;而B题的话只要找准一个切入点,成功的概率非常的大,即便不济,结果也总能忽悠出来的,不会太差。但是另外两名队友经过深思熟虑还是倾向于A题,于是少数服从多数,开始搞A题。第一天还是比较顺利的,我们顺利地解决了第一问,而第二问显然也是基于第一问的,这让我们每个人都面带笑容进入了梦乡——如此下去,第二天晚上就可以搞定第二问,第三天就有一整天的时间来写论文。
三人的分工基本上是这样,解题思路由三人共同商讨,然后lyf负责算积分表达式,ly负责matlab编程和主要的数据拟合,我对LaTeX比较熟,所以除了解题思路和简单的数据处理,主要是看文档、写文档。
第一天的乐观到了第二天的傍晚就变成了焦虑——第二问的积分表达式由于过于复杂以致无法积出来,ly和lyf用matlab算这个符号积分会卡住,我说matlab的符号计算比较弱,于是我在linux平台上找到了著名的符号运算软件maxima,简单配置了Emacs+imaxima,来算这个积分,maxima比较智能,会给你一些提示,比如提示你某个变量是positive, negative or zero? 因为这个变量值不同积分结果也不同。总之积分表达式很复杂,我用maxima算,不同的条件算出来也不一样,有时候算出来竟然是个复数!探索良久,符号积分的方法宣告失败,于是我们转而研究能否用数值积分的方法来算出一部分数据,打表拟合,然后根据拟合的结果判定拟合曲线和实际数据的相似性,确定最后的方程参数。但数值积分是一个比较棘手的东西,除了调用已有数学软件的方法,我们没有能力自己去写。ly和lyf研究matlab,我则找到了maxima的数值积分方法romberg,但是最后也宣告失败,至此,已经是第二天晚上10点多了……士气开始变的低落,ly躺在床上,lyf上网看看别的东西,我也在打酱油般地继续着一些无谓的探索——对于A题,我们已经黔驴技穷,换B题,还剩一天一夜,但是也有些来不及了——更重要的是大家都不太想做下去了。
12号早晨大家都睡到自然醒,心情也不是太好——毕竟没有做出题目是件挺没面子的事情。我提议我们上午再按照打表的方法重新计算一下,然后大家随便算算,到中午基本上就彻底放弃了……于是乎我们就解脱了——ly开始玩一些网页小游戏,lyf上网或者单机游戏,我呢,看完了《当幸福来窍门》,修改了一下午自己的简历,找Ouka帮忙挑了挑刺,投了华为、网易等四五家公司。
13号早晨老师打来电话,问我们论文咋么还不交,我们就坦白交代了说自己没有做出来,论文也没有写,于是我们的CUMCM 2010打酱油之旅就这样结束了。顺便提下这里提供的盒饭还是很不错的,虽然题目没有做出来,但还是赚了三天的伙食——太邪恶了……
离开西溪后冒着小雨骑车到了公司,刚好赶上早会。然后就开始了工作——看,角色转换如此之快。晚上google的宣讲会加现场笔试,七点半到达现场,果然人山人海。8点挤到了位子,开始笔试。笔试总共10道选择和3道编程算法题目,时间是90分钟。选择题大概记得的几道:
- 以下各种排序种哪几种是稳定排序?
- 二叉树的前序、中序和后序遍历中,已知哪两种可以唯一却确定一棵二叉树?
- {1, 2, 3, ..., 20}集合中,挑选出3个数字,使得这3个数字不完全相邻,如{1, 2, 3}, {4, 5, 6},有多少种挑法?
- 32位机器表示的有符号数最小值是多少?
- Unix文件的一道题目?
- 1024!的结尾有多少个零?
- c语言指针的一道题?
- 数组中寻找中位数的算法复杂度是多少?
- 访问内存性能的一道题目。
- 忘了……
剩下的3道编程题目,第一道题目是编程求两个数组集合A[m], B[n]的交集;第二道是离散事件模拟,内容和严老那本经典的《数据结构——c语言版》第3章栈和队列的最后一节一样;第三道应该是桶排序,就是给定n个数,大小均在[1, n^2-1],在保证时间最优的前提下尽可能地优化空间。
google笔试的结果就是我理所当然的被bs了,虽然我觉得答得还算凑合吧,不过连面试的机会都不给,这个招聘也显得有点酱油的味道了——当然,比如像今年的百度之星冠军hh,据说连google的面试官都称之为大牛了,这是另类。
剩下的时间主要是借工作的时间学习,修炼秘密武器,看完了w3c school上的大部分教程,重点是关于XML的,XSL、XPath、XQuery、DTD、Schema等等,研究了Unicode编码的基本知识(UTF-8、UTF-16、UTF-32,Big-Endian,Little-Endian等),研究了python读写excel文件的几个模块(xlrd, xlwt, xlutils, pyexcelerator)和python有关xml的一些模块(lxml, jaxml等),基本完成了《Learning Python》,除了Class看得比较少,剩下的就是熟悉一些常用的mobule,多写写Python脚本,有时间再了解了解Python知名的开发框架,差不多了,剩下的按需学习。
14号是好友Ouka同志的22岁生日,四年前的今日我拿到了化学竞赛的一等奖,收到Ouka祝福短信和亲切指导若干,四年后的今日,我在公司实习,趁午休时间简单改了个小程序,一程序员间独特的方式送出我的生日祝福。Happy Ouka, Fight Ouka。
17号中午回到玉泉,参加了网易有道搜索的机试,两道题,两个小时,zoj平台,20个测试点,总分270,有点类似于NOI,是按照score排名的。结果还是不错的,许久为碰c++,还是拿下了260分,整场50人排名15%左右吧。两道题目如下:
|
给定一个N行,M列的正整数组成的矩阵,求其中的一个子矩阵,使得奇数的个数与偶数的个数差值的绝对值最大 Input 每个文件包含一个测试数据。第一行是两个整数,N,M 表示矩阵的大小 1<=N,M<=100。 接下来N行,每行M个正整数,对应为矩阵中的元素,所有的数不超过2^30。 Output 输出包含一行,为子矩阵中奇数个数与偶数个数差值绝对值的最大值。 Sample Input3 3 1 2 3 3 2 1 1 1 1Sample Output 5 |
|
给定两个整数数组分别为A,B。你可以从A,B中分别挑选一个数,将他们的乘积作为你的得分。你可以挑选任意次,但是每个数只能被挑选一次。 求你最后所能得到的分值和的最大值,你的初始分数为0 Input 每个文件包含一个测试数据。 第一行是一个正整数N,为数组A的长度。 第二行为N个整数,分别为A中的元素。 第三行是一个正整数M,为数组B的长度。 第四行为M个整数,分别为B中的元素。 1<=M,N<=10^6 Output 输出结果包含一行,为你所能得到的最大的分之和。A,B中的数及最后的结果均不超过2^30 Sample Input4 3 2 6 1 3 2 6 3Sample Output 49 |
第一提看上去比较悬,但仔细一想其实是个最大子段和的问题,核心算法可以参考ZOJ 1074——我就是这么干的……应用之前需要预处理,就是扫描下整个矩阵,然后用1表示奇数而用-1表示偶数,最后算“矩阵的最大子段和”,这样做下来基本上可以通过4-5个测试点,弥补的方法就是对称性,考虑到奇数和偶数的平等性,用-1表示奇数而用1表示偶数再算一下。整个程序如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#define size 102
int DP(int a[],int n);
int main(void)
{
int m, n;
int i, j, k;
int he;
int max1, max2;
int a[size][size];
int b[size][size];
int sum1[size];
int sum2[size];
scanf("%d%d",&m, &n);
for(i = 1; i <= m; i++)
for(j = 1; j <= n; j++)
{
scanf("%d",&a[i][j]);
if (a[i][j] % 2 == 0)
{
a[i][j] = -1;
b[i][j] = 1;
}
else
{
a[i][j] = 1;
b[i][j] = -1;
}
}
max1 = max2 = -200000000;
for(i = 1; i <= m; i++)
{
memset(sum1, 0, sizeof(sum1));
for(j = i; j <= m; j++)
{
for(k = 1 ; k <= n ; k++)
sum1[k] += a[j][k];
he = DP(sum1, n);
if(he > max1)
max1 = he;
}
}
for(i = 1; i <= m; i++)
{
memset(sum2, 0, sizeof(sum2));
for(j = i; j <= m; j++)
{
for(k = 1 ; k <= n ; k++)
sum2[k] += b[j][k];
he = DP(sum2, n);
if(he > max2)
max2 = he;
}
}
if (max1 > max2)
printf("%d\n",max1);
else
printf("%d\n", max2);
return 0;
}
int DP(int a[],int n)
{
int i, f[101];
int max = -200000000;
for(i = 2, f[1] = a[1]; i <= n; i++)
{
if (f[i - 1] > 0)
f[i] = f[i - 1] + a[i];
else
f[i] = a[i];
if (f[i] > max)
max = f[i];
}
return max;
}
第二题的思路比较清晰了,需要注意的是负数的情况,考虑四个正数 ,显然
,显然 ,就是要得到最大值,大大相乘优先。如果遇到负数,负负为正是可以考虑的,正负相乘则需要舍弃。按照这个原则进行排序、分割,在处理下去就不难了。有一个Test Case是Segmentation Fault,最后找到原因了,可惜没有时间了,程序如下:
,就是要得到最大值,大大相乘优先。如果遇到负数,负负为正是可以考虑的,正负相乘则需要舍弃。按照这个原则进行排序、分割,在处理下去就不难了。有一个Test Case是Segmentation Fault,最后找到原因了,可惜没有时间了,程序如下:
#include <iostream>
#include <algorithm>
#include <vector>
#include <functional>
using namespace std;
int main()
{
int m, n;
vector<int> a;
vector<int> b;
int i, j;
int item;
int s, sum;
int ai, bi;
cin >> m;
for (i = 0; i < m; i++)
{
cin >> item;
a.push_back(item);
}
cin >> n;
for (j = 0; j < n; j++)
{
cin >> item;
b.push_back(item);
}
sort(a.begin(), a.end());
sort(b.begin(), b.end());
for(i = 0; i < a.size(); i++)
{
if (a[i] >= 0)
{
ai = i;
break;
}
}
for(i = 0; i < b.size(); i++)
{
if (b[i] >= 0)
{
bi = i;
break;
}
}
sum = 0;
for(i = 0, j = 0; (i < ai) && (j < bi); i++, j++)
{
sum += a[i] * b[j];
}
for(i = a.size() - 1, j = b.size() - 1; (i >= ai) && (j >= bi); i--, j--)
{
sum += a[i] * b[j];
}
cout << sum << endl;
return 0;
}
最后的结果还是不错的,这也让我感到惊喜,好久都没有如此开心过了,期待面试通知。
另外,现在所在的实习公司已经有了口头上的offer,给我一个月的时间考虑,在实习结束之前给答复,待遇和淘宝应届是差不多的,而且创业阶段,发展空间还是非常大的,我在部门也受到重视,我相信继续实习一年,毕业后我会处于一个比较高的起点,这样的结果,对于我这么一个挂科达到两位数的刚毕业的本科来说,应该算很不多的了,但是我还是在犹豫。老实说我还是想去大的公司体验两年,体验下大的平台和大的气质;妈妈每次打电话都让我回北京,家近、方便。所以我还在继续投简历。
18号下去2:00-3:00,百度大牛徐串的技术讲座;19号下午2:00,百度内推小型见面会;20号晚6:30,MSTC主席pluskid大神的小课堂,各种大牛,膜拜。
除了这些,印度宝莱坞的电影《三个傻瓜》前前后后看了4遍,哭笑中带来人生的思考;看了《当幸福来敲门》,我喜欢那种“He must have a nice pants”的自信;看了柴静的《面对面》——李连杰“壹基金危机”,“侠之大者,为国为民”,李连杰当之无愧;“方向对了,就不怕路远”,加油吧,Lox!