CloudComputing - 行者无疆 始于足下 - 行走,思考,在路上
OpenStack开发杂谈
去年12月份的时候我曾经给自己写了一份"OpenStack开发基础知识"书单,贴在墙上,书单大概如下:
- 网络基础:
- 语言基础:
- JavaScript:
- Web Design
- +Rabb+itMQ in Action
- Database
- Django
读书进度=书名中划线部分的长度/书名的长度。之所以有这份书单,是因为在前面几个月的开发中,我发现自己的基础知识薄弱,远远不能满足OpenStack开发的需要。虽然自己已经能够按照公司的基本要求,照猫画虎地开发出几个能用的所谓Feature,但是我内心明白,自己的能力上尚不足以透彻理解OpenStack代码1。
我认为自己还算是一个比较努力的人,并且自认为对自己目前所从事的行业还是有着满心的热爱和期待,期待自己能做出一些有用的产品,留下一些真正有用的能改善人们生活的东西。这个宏大的愿望映射到眼前,就是努力使自己成为一个合格的Full-Stack类型的Web开发工程师。而进一步将眼前目标付诸行动,就是上面的书单了。我原本定的时间是3-5个月左右,不过现在看来还是太狂妄太浮躁了。客观上是自己要工作,时间不完全都是自己的;主观上则是自己“深度优先,随性而为”的阅读习惯常常会不自主的打乱原本订好的读书计划。比方说我在读"Pro Python"的时候为了搞清楚细节会去读"Python源码剖析",会去尝试理解Python的整个历史;在读"HTTP"的时候为了理解ReST,会去读"REST in Practice"; 而我在尝试理解Python TDD的时候会把Ruby中关于Cubumber的书加入阅读计划。这或许不是一个良好的阅读习惯,但这能保持我的兴趣,这就够了。
我不是一个Top的工程师,至少目前不是——Top的工程师不会像我一样还在费力的学习理解ReST/TDD这些概念性的东西。我知道Top的工程师在哪里 2。这类人天赋异禀,并且在很早的时候就接触计算机。在你还在骑着自行车围着院子绕圈的时候他们已经开始理解算法和数据结构,在你刚刚写出"hello world"的时候他们已经能写出成型的软件作品,在你毕业之际为找工作焦头烂额的时候,他们已经受过了1万小时的训练,有更好的机会和最聪明的人合作更快的提高自己。这个博客基本上忠实记录了我正式开始认真学习计算机的全部历程。四年来我几乎做过各种各样的东西,Windows手机开发,Java SSH(已经忘光光),OpenGL程序,Hadoop,Python/FFmpeg写的转码系统等等,很杂,也很浅。但我一直坚持一个方向,就是拥抱开源,先是尝试学习基础知识,用好Linux/Emacs这类基本工具,毕业工作后开始去尝试读一些开源代码,提一些无关痛痒的patch试图接近开源,这一年来又开始尝试理解OpenStack,并真正的提交了一些patch。我不敢评价OpenStack的设计是否优秀,事实上我还没有这个能力去完全理解它,更妄论评价了。但是OpenStack的开发确实让我学到了很多东西,我开始理解了TDD,开始逐理解了ReST和Web Service,开始逐渐理解作为工程语言而不是脚本语言的Python,开始理解Message Queue。而我也通过自己的努力,让基于jenkins/gerrit的自动化测试部署的全套流程在公司运转了起来。
两年前信心满满刚来北京的时候,我从未想过自己会那么快的离开百度3,一年前开始寻找新的工作机会的时候,我完全没有听过OpenStack这个词。当初一心坚持离开学校是为了远离校园里学习的束缚,现在走向工作岗位又会感慨感叹时间的宝贵和校园里相对的自由。说白了,我是一个贪心的实用主义者,胸无大志,从来不会想五年以后的事情,学校里面不想听无聊的课程,就天南海北山山水水的疯跑,哪怕一学期挂科五门依然无所畏惧不懂屈服;工作以后顶撞上司就来个偷得浮生半年闲,躲进小楼成一统,管他春夏与秋冬,云卷云舒花开花落——但为了生活还是要出来找工作。
貌似扯的有些远了……最后回到本文的正题吧,OpenStack的开发。上个星期做了两个东西,第一是做了个OpenStack代码的国内镜像,方便教育网内学生党4,地址是:
第二是基于Vagrant做了个OpenStack的开发环境,地址是:
- https://github.com/xiaohanyu/vagrant-hackerbox
- https://github.com/xiaohanyu/vagrant-ansible-devstack
好了,吹牛到此结束,各位好梦晚安。
--
Footnotes:
1 比如我至今依旧没完彻底理解OpenStack中基于sqlalchemy ORM的数据模型,基于iptable/openvswitch等的底层网络原理,更妄想理解kvm/xen/内核这类CS工程领域真正“高富帅”的东西了。事实上,如果没有扎实的数据库/网络/操作系统知识,要彻底理解这些东西是很难的。
3 也从未想到过自己的一篇文章能引起那么大的争议。
4 顺便吐槽下北大的校园网,30元/80小时,50元/160小时,90元不限时包月,超时流量1元/MB,这价格都快赶上北京正常的联通宽带了。而且速度那么慢(github clone 20k/s),北京联通现在可是号称20M光纤入户的。这就是世界一流大学的校园网,可笑。
闲谈MapReduce(1): Hadoop初探
Table of Contents
1 缘起
MapReduce是这几年IT界很热的一个名词,从某种意义上讲,MapReduce引领了当代海量数据处理的趋势和潮流。与IT界的其他名词一样,MapReduce听起来也是个很玄乎的名词,MapReduce?Map?Reduce?如果你是一名初级Coder,那么你可能从某处知道,Map的翻译是映射,Reduce的翻译是归约。MapReduce就是映射归约,是一种数据并行处理的一种编程模型。如果很不幸,你不是一名光荣的Coder,只是中国网民大军中的五万万分之一1,那么没关系,MapReduce离你并不遥远,有一个名词你一定很熟悉,那就是——云计算。关于云计算,互联网上有一个经典笑话,“中国一留学生去美国打工的当过报童,不带计算器,习惯动作抬头望天时心算找零。顾客大为惊讶,纷纷掏出计算器验证,皆无误,也抬头望天,惊恐问:“云计算?”不过云计算的真正含义,用工程师的语言,准确地定义,应当是“超大规模的,可扩展的,低成本,但是高可靠性的服务器集群系统”2。
从大的层面上来讲,云计算并不仅仅是MapReduce,MapReduce只是云计算的一个技术性开端,或者说,是互联网的发展需求推动技术的发展进步,最后由Google临门一脚创造出来的一种处理海量数据的并行编程模型。真正的云计算包含诸如IDC建设、海量存储、网络规划、商业模式、网络安全等等诸多技术的难题,还有很多被一些所谓的专家炒作起来的社会意义。不过本系列文章并不打算探讨这些过于宏大的主题,我本人也没有这样的水准和资格来说三到四。本系列文章的目的只有一个,那就是搞明白,MapReduce中的Map和Reduce,到底源自何处3?
我第一次听说MapReduce这个名词,是在2010年9月,那时百度来浙大宣讲,顺带开了一个技术讲座,主讲人徐串曾是Google中国编程挑战赛冠军。当然,讲座内容我是听不懂的,随心记下来的几个技术名词,至今为止,还能记住的,只剩下MapReduce了。后来面试百度运维部,期间和面试官聊到我暑期实习在华数淘宝做的一个视频转码入库系统,面试官大概觉得这个系统有点分布式的意思,因此题目结束的时候给了我一个建议,就是让我学习下MapReduce。再后来,阴差阳错,我进入了百度的分布式运维小组学习Hadoop运维,学习MapReduce就成了一个身不由己的任务。
在百度的半年,我初步接触了大规模Hadoop集群(3000个节点的规模)的运维工作。但比较讽刺的是,运维Hadoop集群的我,自身并没有写过多少真正的MapReduce程序,对Hadoop的理解也浅尝辄止。而我也始终没有搞明白,好端端的一个程序,为什么要按照MapReduce这样别扭的模型重构运行?
大概是看了Paul Graham的《黑客与画家》后,我开始正式认真学习Lisp这门语言,至今已有小半年时间,这期间我利用业余时间,和最近一个月的休假时间,基本上看完了Paul Graham的《ANSI Common Lisp》和《On Lisp》,《SICP》太难,我穷尽脑力至今也只窥得前面三章,做了100道习题左右,不过即便如此,也令我受益匪浅4。半年Lisp的学习让我搞明白了MapReduce中,Map和Reduce的来龙去脉。这个问题我Google了很久,但是始终没有一个满意的答案,现如今,我自己找到了满意的答案。
2 抽象漏洞(兼谈数学和计算机工程)
在正式开始我们的探险之旅前,我们还面临这一个问题,那就是,这次探险的必要性在哪里?既然MapReduce已然为我们提供了成熟的理论编程模型,Hadoop生态圈也给我们提供了一整套成熟的工程实现,我们为什么还要纠缠这些学究般的历史问题?我的解答是, 一个学科的历史往往就是这个学科的本身 。无论是一门编程语言、编程范式、编程模型,或者IT业的任何一项新技术新名词,在学习的过程中,一定要搞明白:
- 它解决了什么样的技术问题?当时的历史背景是什么?还有没有类似的(可能没有流行起来的)解决方案?
- 它的引入带来了哪些新的问题?
- 它的优点是什么?什么样的问题一定会手到禽来?
- 它的不足是什么?什么样的问题是它解决不了的?
这就好比解一道很难数学题,如果光告诉你一个正确的数字,那么这个数字对你来说一点意义都没有;如果进一步,告诉你标准的解题过程,那么你可能会对这个题目有一个粗浅的认识;如果有那么一个白痴,不但告诉你正确的答案和解题过程,还把他的演算纸送给了你,并热切地给你讲解他在解题过程中碰到了哪些问题和陷阱,是怎样解决怎样解决问题怎样规规避这些陷阱的,那么你对这道题目的理解则会大大加深,日后再碰到同样类型的问题就会轻车熟路,手到拈来。 从某种意义上而言,一个完整的解题的探寻过程才是一个题目所具有的全部信息价值,扔掉这些而仅仅记住一个解题结果或者一个标准的解题证明,无疑是买椟还珠 5 。但是比较可悲的是,计算机是一个年轻的学科,所以专门讲述计算机历史的书籍并不像数学史书籍一般汗牛充栋。
从另一个角度上讲,计算机和数学的都是一座不断分层的抽象大厦。数学是从基本的整数,到数系的扩充,到微积分的诞生,到非欧几何等等宏大的诗篇;而计算机则是从最基本的与非门,到bit、byte、word,到汇编、c、高级语言,到设计模式、分布式等等现代工业的大厦和基础。“计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决6”,不过很不幸, 计算机的抽象和数学的抽象有一个本质的不同,那就是计算机的抽象是有漏洞的 ,这就是抽象漏洞法则:All non-trivial abstractions, to some degree, are leaky。在数学领域,我们从来不用担心说某个定理“因为空调故障的原因宕机了,或者因为内存吃紧运行特别缓慢,似乎是发生内存泄漏了”,等等诸如此类的各种各样令人头疼的问题。这条法则深刻的影响了计算机软件和数学定理的生产过程——在计算机中,我们不可能找到一个能困惑世间智者358年的谜7;在数学领域,我们也不可能找到一个耗费人类5000万人年人力的定理8。 如果说,基于抽象的数学,考验的是人类大脑思考深度的极限,那么同样是基于抽象,并且脱胎于数学的计算机工程,挑战的就是人类大脑思考广度的极限 ——软件工程中瓶瓶罐罐的细节太多了,所以大凡软件开发,走的都是兵团作战的策略;而数学就不一样,“10个产妇无法在一个月内生出孩子9”,数学领域中辉煌定理的产出,往往依靠少数几个,甚至单个天才数学家的苦苦思索和灵感涌现。
3 Let's Go
以上,废话了这么多,所要强调的无非就是,了解MapReduce的来龙去脉,对于写出更好的MapReduce程序,甚至将来拨开层层抽象,解决MapReduce的底层问题,乃至改善MapReduce,都是大有裨益的。不过,在正式踏上我们的探险旅程之前,我们需要检查一下手头的“装备”是否合格,很简单:
- 你需要一台*nix系统,最好是GNU Linux,苹果也行,如果实在不方便,Windows下装个Cygwin也还能凑合;
- 你需要有一定的编程经验,包括但不仅限于C、Java、Bash、Python,如果再对Lisp或者Scheme有一定了解就更好了(别急,本系列文章对Lisp做一个简要的介绍);
- 你需要了解一些常见的*nix软件开发工具,包括但不限于Vim的使用、Ant和Make构建工具、Git和SVN版本控制软件;
- 你需要对POSIX系统标准有一定了解,包括但不限于*nix的文件系统结构、用户属组、文件权限、管道等等。
Now, Let's Go!
4 Hadoop
行文至此,相信众位读者已经知晓了云计算的一些基础概念,最起码知道了所谓Google技术的三驾马车是什么,如果能看过Hadoop代码中WordCount的例子并能看懂的话,那你简直是太天才了。为了保证我们的探险顺利进行,我们需要一套开源的MapReduce平台实现来验证我们的学习成果,Hadoop是不二选择。关于Hadoop本身有太多太多的资料,因此我在这里就不再劳心劳力的copy别人的劳动成果了。推荐以下三本书,作为Hadoop的入门:
我们所要做的,就是在本机的*nix系统下,搭建一个demo的伪分布式运行的Hadoop平台。我采用的Hadoop版本是Hadoop 0.20,这个版本比较稳定,最新的Hadoop 1.0添加了很多新的特性,这些特性对于我们的探险并没有特别的作用,而且我也不甚了解。当然,本文的重点并不是Hadoop,所以我并不会带你去分析HDFS的源代码,告诉你如何打Patch(我也不会,嘿嘿)。本文的重点在于MapReduce的来龙去脉。
- 首先本机*nix上存在jdk和ssh,并找到相应的$JAVA_HOME
- 首先是建立本机用户到自身的ssh信任关系,步骤大致如下:
➜ ~ ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/home/lox/.ssh/id_rsa): /home/lox/.ssh/id_rsa already exists. Overwrite (y/n)? y Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/lox/.ssh/id_rsa. Your public key has been saved in /home/lox/.ssh/id_rsa.pub. The key fingerprint is: 19:3f:55:84:99:d2:1e:c6:42:d0:39:6f:3e:83:84:21 lox@lox-pad The key's randomart image is: +--[ RSA 2048]----+ | .+.+ =o | | E . * O. | | ..o B.. | | .+..+ | | S.o+ | | ..+ | | o | +-----------------+ ➜ ~ cp .ssh/id_rsa.pub .ssh/authorized_keys ➜ ~ chmod 700 .ssh ➜ ~ chmod 600 .ssh/authorized_keys ➜ ~ ssh lox@localhost
- 下载hadoop v0.20,解压缩到一个目录,我的目录结构如下,其中tmp/hadoop-data作为hdfs数据存放目录(包括伪分布式运行的namenode和datanode的数据),tmp/hadoop-v20作为$HADOOP_HOME
➜ ~ tree -L 1 tmp/hadoop-data tmp/hadoop-v20 tmp/hadoop-data tmp/hadoop-v20 ├── bin ├── build.xml ├── CHANGES.txt ├── conf ├── conf.origin ├── conf.pseudo ├── conf.standalone ├── contrib ├── docs ├── hadoop-0.20.3-dev-ant.jar ├── hadoop-0.20.3-dev-core.jar ├── hadoop-0.20.3-dev-examples.jar ├── hadoop-0.20.3-dev-streaming.jar ├── hadoop-0.20.3-dev-test.jar ├── hadoop-0.20.3-dev-tools.jar ├── ivy ├── ivy.xml ├── lib ├── LICENSE.txt ├── logs ├── NOTICE.txt ├── README.txt ├── src └── webapps
-
修改hadoop的配置文件分别如下:
- hadoop-env.sh,重点修改下$JAVA_HOME,指向SUN JDK或者OpenJDK的目录,Hadoop官方建议采用SUN(现在是Oracle啦)的JDK。
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
hadoop-env.sh ... ... # The java implementation to use. Required. # export JAVA_HOME=/opt/java export JAVA_HOME=/usr/lib/jvm/java-7-openjdk ... ...
core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/lox/tmp/hadoop-data/tmp</value>
</property>
</configuratione>
hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/lox/tmp/hadoop-data/name</value>
<final>true</final>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/lox/tmp/hadoop-data/data</value>
<final>true</final>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>5</value>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>5</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx512m</value>
</property>
</configuration>
- 启动hadoop,如果能用Hadoop FS Shell做一些常规的mkdir和ls操作,Hadoop搭建就算大功告成了:
➜ ~ hadoop namenode -format 12/02/15 00:07:23 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = lox-pad/127.0.0.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.20.3-dev STARTUP_MSG: build = http://svn.apache.org/repos/asf/hadoop/common/tags/release-0.20.2 -r 916569; compiled by 'lox' on Wed Nov 9 23:40:01 CST 2011 ************************************************************/ Re-format filesystem in /home/lox/tmp/hadoop-data/name ? (Y or N) y Format aborted in /home/lox/tmp/hadoop-data/name 12/02/15 00:07:25 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at lox-pad/127.0.0.1 ************************************************************/ ➜ ~ start-all.sh starting namenode, logging to /home/lox/tmp/hadoop-v20/bin/../logs/hadoop-lox-namenode-lox-pad.out localhost: starting datanode, logging to /home/lox/tmp/hadoop-v20/bin/../logs/hadoop-lox-datanode-lox-pad.out localhost: starting secondarynamenode, logging to /home/lox/tmp/hadoop-v20/bin/../logs/hadoop-lox-secondarynamenode-lox-pad.out starting jobtracker, logging to /home/lox/tmp/hadoop-v20/bin/../logs/hadoop-lox-jobtracker-lox-pad.out localhost: starting tasktracker, logging to /home/lox/tmp/hadoop-v20/bin/../logs/hadoop-lox-tasktracker-lox-pad.out ➜ ~ jps 21061 JobTracker 20852 DataNode 21255 Jps 20977 SecondaryNameNode 20764 NameNode 21156 TaskTracker ➜ ~ hadoop fs -mkdir /tmp/this-is-a-test-dir ➜ ~ hadoop fs -ls /tmp Found 1 items drwxr-xr-x - lox supergroup 0 2012-02-15 00:08 /tmp/this-is-a-test-dir ➜ ~
好了。基础工作已经准备好,在接下来的旅程中,我会初步讲解一下Hadoop的基本概念和使用方法,进而转入Lisp(Scheme)函数式编程的美妙世界,带你逐本溯源,领略一下原生态的Map和Reduce到底是什么模样,并且会顺带谈到一些我在Lisp学习过程中领略到的别样风景,包括但不限于Java的反射、序列化等一些高级特性,XML、JSON的数据语言的特性特点等等。敬请期待!
--
Footnotes:
1 第29次中国互联网络发展状况统计报告显示,2012年初,中国网民共计5.13亿。
2 关于这个定义的出处可以参考弯曲评论上一篇非常好的关于云计算的科普文章“云里雾里云计算”,本文不打算探讨云计算的社会意义、产业变革、安全等过于宏大的主题(其实我对这些一点都不了解)。
3 MapReduce的第一篇论文"MapReduce: Simplified Data Processing on Large Clusters"曾写到:"Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages."可见,MapReduce的思想来自于古老的Lisp语言。
4 广告一下,在我有限的阅读经历中,《SICP》是我读过的计算机书籍中最棒的一本,没有之一。如果能认真做完这本书里面的356道题目,绝对会让你对编程本质的理解有一个脱胎换骨般的提高。这里有我个人的部分习题解答代码和学习笔记。
5 关于这一点,刘未鹏的《知其所以然》系列文章里有更好的解读,我就不再重复了。
8 据《Unix编程艺术》的序言里的脚注:“从1969年到2003年,35年世间并不短。以这期间众多Unix站点数量的历史曲线来估算,人们在Unix系统的开发方面投入了约5000万人年”。
9 这原本是Brooks's Law的一种观点。
Issues of Eclipse Helios with Hadoop
最近在搞Hadoop MapReduce,在本机配置了个Hadoop Pseudo环境,就琢磨着写两个Java小程序练练手。而Java程序开发的初始配置一向以麻烦著称,记得大二时开始学习Java时对那个CLASSPATH环境变量晕了好久。所以这个时候选一款顺手的IDE就是很重要的了。
另一方面,对于长期生活在K.I.S.S环境的geek来说,对IDE通常是不感冒的。他们更喜欢a+b+c+d+Emacs或者Vim+w+x+y+z的组合。但是Java就不同了。Emacs虽然有JDEE,但是Emacs没有好用的jsp-mode,好像也没有自动打包发布部署的功能,或者即使有,也需要极其麻烦的配置。而且Emacs的代码不全功能一向很麻烦也不太好用,对于Java巨大的类库和超长的类名就更头大了。所以在血淋淋的事实面前,我还是屈服了。好在还有个Eclipse。
为什么是Eclipse而不是NetBeans?其实没啥特别的原因,就是Eclipse的界面更加和谐一点,对Java Swing的丑陋效果和蜗牛般的速度实在是心有余悸。Eclipse确实也是非常优秀的软件,跨平台,多语言,丰富的插件和和谐统一的插件安装系统,良好的社区支持。Emacs也是。
好了,废话少说,说说今天纠结的Eclipse Hadoop之旅吧。我用的软件版本是Eclipse 3.6,安装的时候顺便将eclipse-cdt也装上了:
pacman -S eclipse eclipse-cdt
启动Eclipse一切正常,试着建立一个Project却发现无论如何也找不到C++的项目,照理说不应该,不过不打紧,C++和今天的主题无关。继续。
Eclipse开发Hadoop MapReduce程序需要安装一个hadoop eclipse plugin,而根据Eclipse和Hadoop版本不同,所需选择的插件也不一样,有官方hadoop contrib里的jar包,有google code上的,还有打过patch的山寨jar包。而eclipse安装插件的方法也有很多,比如:
- 安装到plugins目录
- 安装到dropins目录
- links方式安装
- 通过Help-->Install New Software的方式安装
- ……
而我排列组合搞了一个下午后,Eclipse 3.6的Hadoop插件还是没有装上。无奈在AUR上安装了Eclipse 3.5:
yaourt -S eclipse-classic-galileo
然后将eclipse-hadoop-plugin放到plugins目录下,终于看到了可爱的小象。究竟是怎么回事呢?
定位好久,还是没有任何头绪。首先是eclipse没有Linux Manual,输入eclipse --help也没有任何信息,所以我不知道eclipse CLI有没有什么可用的参数;其次是我不知道eclipse有没有自己的log,或者有我也不知道在什么位置,无法发现启动过程中的蛛丝马迹。
此时已经有些心灰意冷,寻思着要不就用Eclipse 3.5得了。无意中在网上发现了Hadoop的另一个插件,Karmasphere,看了下介绍还是蛮强大的,而且有community和professional两个版本,前者是免费的,只是下载的时候需要简单注册下。最重要的是,这个插件有Eclipse和NetBeans两个版本,真实太令人激动了。照着教程配只好NetBeans 6.9的开发环境,可以用,很强大。于是心情大好,继续配置Eclipse 3.6版本,这下Eclipse 3.6无法安装插件的问题终于露出了狐狸尾巴:
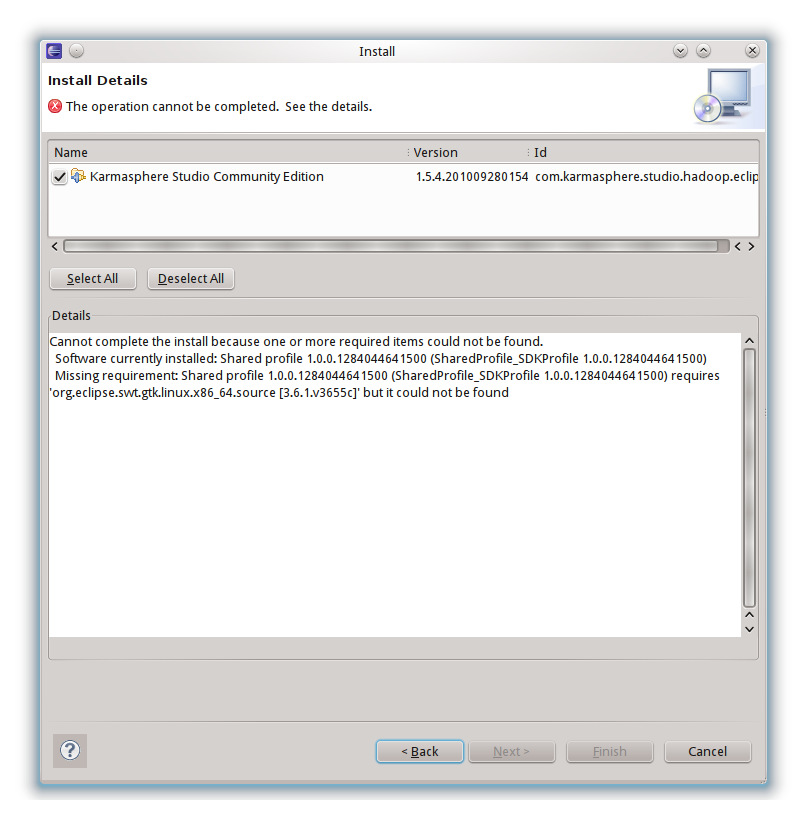
重点是"requires 'org.eclipse.swt.gtk.linux.x86_64.source [3.6.1.v3655c]' but it could not be found"。赶紧定位下org.eclipse.swt.gtk.linux.x86_64:
% sudo updatedb && locate org.eclipse.swt.gtk.linux.x86_64 /usr/share/eclipse/plugins/org.eclipse.swt.gtk.linux.x86_64.source_3.6.1.v3655c.jar /usr/share/eclipse/plugins/org.eclipse.swt.gtk.linux.x86_64_3.6.1.v3655c.jar
可以肯定的推断,这个东东在系统中是存在的,虽然命名方式可能不太一样。接下来的问题就好办了很多。我怀疑是/usr/share/eclipse目录的读写权限问题。在这里我的想法得到了佐证。于是立马改了/usr/share/eclipse的读写权限:
sudo chown -R lox:users /usr/share/eclipse
重启Eclipse 3.6,果不其然,CDT复活了。于是又安装了Eclipse-hadoop-plugin和karmasphere的plugin,总算大功告成。
最后放一张图吧: