行者无疆 始于足下 - 行走,思考,在路上
Knight Rush——关于编程语言学习的一些思考
1 引子的引子
金庸小说里的大侠们在行走江湖时,向来都是衣来伸手饭来张口,一不小心心情郁闷了还可以来个金盆洗手、笑傲江湖,就是从来不会考虑钱的问题。我不是大侠,生活也不是小说,“退隐闭关”半年啃了几十本书后,生活还是要继续。这几日满京城地找工作,各种笔试面试聊技术聊人生,也让我对自己的技术体系和职业规划做了一次全盘扫描,快哉快哉。
2 引子
前几日面试了一家专注云计算的创业公司易云捷讯,一面是公司创始人 从美国打来的越洋电话,聊什么我已经记不太清楚了,其中有一道题目是关于Fibonacci数列的,这个恰好问到了我的G点上,于是我就将我在《SICP》 上学到的什么快速乘法啊、尾递归啊、迭代和递归啊啥的和盘托出,大大地吹嘘了一番,总之感觉还不错,算是了给面试官的一个小惊喜,就这样胡乱通过了一面。一面之后邮件沟通被分配了一道编程题目,大意如下1:
在一个国际象棋棋盘上(N*N),有一个棋子"马(Knight)",处在任意位置(x, y);马的走法是日字型,即其可以在一个方向上前进或后退两格,在另一方向上前进或后退一格。请编程找出马如何从位置(x, y)走到棋盘右下角(N, N)的位置的步骤。例如:假设棋盘大小为3*3,马处在(1,2)位置,马只需要走一步,即 (1,2)->(3,3)即可到达目的地。编程语言推荐的是Python,程序能输出一种可行的方法即可(无需找出所有方式),还有一些软件工程的要求诸如文档、注释、代码风格这些“无关痛痒”的东西。
我是第一次在应聘时碰到这种不限时间自由rush的题目,坦白的讲,我还是比较喜欢这种形式的题目的。纸上谈兵的笔试有点八股,ACM般的机试时间又太紧,面对面的聊天或者刺刀见红般的白板写代码算是比较好的了解一个人技术水平的手段,但是这三种方式的考核方式其实都和真实的工作流程相左;而这种rush类型的题目基本上可以反应一个人工作能力——你可以利用google、可以去查算法书籍、可以在有限的时间内再去学习一些技术,唯一要求的就是诚信。
我看到此题的第一想法就是暴力试探法,因为对于knight p(x, y)而言,p(x-1,y), p(x+1, y), p(x, y-1), p(x, y+1)四个方向上相邻的点都是可达的。按此思路只需要“步步为营,稳扎稳打”就可以到达“胜利的终点”p(N, N)。
显然,这种策略不是对方想要的结果。适逢夜深燥热、大脑混沌,且先睡去,待次日云淡风清,再做打算。果不其然,早起在“响应大自然呼唤”的时候,我想到了理论上的最佳解决方案,不但能给出一条可行的路径,而且这条路径保证是最短的。聪明的你或许已经想到,没错,这个题目本质上就是一道unweighted undirected shortest path的图论问题。转换的方法很简单:从左到右从上到下,将(N*N)的棋盘上N*N个point顺次编号为0, 1, … N*N-1,对于棋盘上的一个点p(x, y),按照knight的走法,其下一步到达的点最多有8个:p1(x-1, y-2), p2(x-1, y+2), p3(x+1, y-2), p4(x+1, y+2), p5(x-2, y-1), p6(x-2, y+1), p7(x+2, y-1), p8(x+2, y+1),所有这些点的集合构成了点p在unweighted undirected graph中的邻接表。接下来BFS算一下最短路径(由于是无权图,因此还是不劳烦Dijkstra大侠的高招了,简单的BFS就够了),再做一些简单的输入输出和错误处理就OK啦。那么最后的一块骨头就是Coding了。
我最后大概花了15个小时左右完成了C++/Lisp/Python三种不同语言的程序,三者的Coding时间比大概是5:2:3,这也是我第一次用不同的语言来写同样的程序,原本想起来不算太难的工作,写完后还是很有收获的2,勿在浮沙筑高台,Coding这种工匠手艺活,眼高手低是最要不得的。
文既至此,我就顺便谈谈语言学习的问题,高贤见笑后,如有时间,万望不吝赐教。
3 C++
按照我所了解的当代中国本科计算机教育,大多人工科学生学习的第一门编程语言应该是C,接下来如果还有需要的话,就是C++或者Java了。不幸的是,鄙人也是这样过来的,幸运的是,鄙人天资愚鲁,学了半年C++后知难而退,转战了实战主义的Shell Script和Python,这一年来闹中取静,为了探寻MapReduce算法模型的本原,啃了几本Lisp的书,回过头来,总算对C++的诸多繁杂特性有了一些全局性的认识,这种认识来自于跨语言的佐证和思考,而非来自于C++语言本身。事实上C++中的很多概念在C++中是无法学到通透的,比如:
- C++11的lambda:你可以不知道Alonzo Church, 也可以不会Lambda calculus3, 但是如果你不知道什么叫Higher-order function4的话,你怎么好意思说,你会lambda?lambda仅仅是匿名函数那么简单吗?匿名函数有何用?匿名函数的递归问题怎么解决5?STL里的functor究竟是语言机制设计的经典还是为了弥补语言不足所贴的狗屁膏药?
-
STL:STL几乎就是C++经典库和设计的代名词,通过迭代器将算法和组件分离6,力求达到性能和代码重用的双重顶点。
- 可惜你不知道的是,迭代器并不是一个高层次的抽象机制,迭代器的本质是一种迭代遍历操作,至于通过什么手段来迭代遍历,这些本不应该是使用者所应该关心的细节问题。所以对于下面的这段c++伪代码:
for (vector<int>::iterator itr = v.begin(); itr != v.end(); ++itr)
{
do_something(*itr)
}
-
- 其高阶抽象代码应该是:
for_each(v, do_something)
-
- 稍微了解一点Lisp的读者都能想到如下的等价伪代码7:
(mapcar #'do_something v)
-
- 每次你写"v.begin(), v.end()"这样的代码时,你就不知不觉地降低了自己的抽象层次,使自己脱离问题域而转向去纠结于实现域,不要小看这种力量, 软件工程的一切欢乐和痛苦,只是聚沙成塔的两个极端而已。
- 事实上STL本身包含很多函数式编程的思想,比如说 functor这种组件,其实质是将在c++中作为second-class的函数通过类封装的手段提升至first-class,如此一来,函数的核心操作摇身一变成为functor的时候,就可以像函数式语言里面的Higher-order function一样,可以用类成员变量来模拟实现闭包,可以被当做普通参数传递返回(这样就不用费力去写令很多新手语法不过关的函数指针了),甚至可以通过std::bind1st/std::bind2nd这种奇技淫巧实现一个蹩脚的线性代数级别的函数映射与变换。8
- STL里面大量的算法都是基于迭代器的抽象而进行序列的批量化操作,同种算法多种容器的核心技术是 基于C++模板实现的静多态 ,"It is better to have 100 functions operate on one data structure than 10 functions on 10 data structures",从这个角度上来讲,STL算法和Lisp中针对sequence类型数据的各种函数(mapcar/remove/remove_if/member等)有异曲同工之妙。
- 最后来八一八STL之父Alexander Stepanov,其实人家是莫斯科大学数学系毕业的高材生,所以STL背后有着很深的数学思想,"Elements of Programming"或许是解开这个谜题的钥匙。另外,Alexander是反对OOP的。
-
泛型与模板:这大概是Modern C++中最重口味的话题了,也是很多C++初学者的噩梦。我认为C++模板足够强大,但同时也足够扭曲且非人道,布满了大大小小的地雷和陷阱。探究起来,C++模板之所以有那么多坑,其历史原因在于C++模板是一种被发现而非被发明的技术9。C++最初引入模板的动机非常简单,无非就是写一些通用的min/max函数和一些简单的泛型类,但是人们后来发现C++模板竟然是图灵完备的,这件事极大的刺激了C++程序员的神经,于是乎,一个又一个神乎其技的ad hoc的模板编程的奇技淫巧被挖掘出来,这些奇技淫巧分布在C++标准库的各个角落,而这些奇技淫巧本身也成了许多C++程序员绕不开躲不过的必修课。C++的学习就像练剑一样,练到一定境界总会碰到这样那样的瓶颈,这个时候很多人就会认为自己功力不够,或者是练得不够刻苦,于是乎找来一本又一本的“武功秘籍”10更加刻苦地练剑。殊不知,如果方向不对,再怎么努力刻苦也难免事倍功半。你可知道,繁杂的C++模板特性的背后,其本质到底是什么?
-
C++模板的本质在于用编程的手段显式地控制编译器的代码生成。没错,聪明的你已经想到,Lisp的macro做的也是同样的事情。但是不同于Lisp的macro,由于C++模板的先天不足和C++静态类型系统的限制,C++在语言层面上对模板编程的支持非常有限。荣耀先生有一篇非常精炼的PPT《C++模板元编程技术与应用》, 基本上概括了C++模板编程的核心机制和语言实现,我摘录了一些如下:
- 模板元编程使用静态C++语言成分,编程风格类似于函数式编程,其中不可以使用变量、赋值语句和迭代结构等。
- 在模板元编程中,主要操作整型(包括布尔类型、字符类型、整数类型)常量和类型。被操纵的实体也称为元数据(Metadata)。所有元数据均可作为模板参数。
- 由于在模板元编程中不可以使用变量,我们只能使用typedef名字和整型常量。它们分别采用一个类型和整数值进行初始化,之后不能再赋予新的类型或数值。如果需要新的类型或数值,必须引入新的typedef名字或常量。
-
编译期赋值通过整型常量初始化和typedef语句实现。例如:
- enum { Result = Fib<N-1>::Result + Fib<N-2>::Result};
- static const int Result = Fib<N-1>::Result + Fib<N-2>::Result;
-
成员类型则通过typedef引入,例如:
- typedef T1 Result;
- 条件结构采用模板特化或条件操作符实现。如果需要从两个或更多种类型中选其一,可以使用模板特化,如前述的IfThenElse11。
- 静态C++代码使用递归而不是循环语句。递归的终结采用模板特化实现。如果没有充当终结条件的特化版,编译器将一直实例化下去,一直到达编译器的极限12。
- 而正是由于底层支撑性语言机制的匮乏,使得C++模板编程非常的冗长、丑陋,甚至有些扭曲乃至非人道13。我以为,用一门连IfThenElse都要靠Hack去实现的子语言去写高阶代码,和用汇编语言去写高级数据结构是差不多的。所以你去看STL的代码,看std::binary_function,你会发现大量的typedef做类型推导。可是你想过没有,类型推导真的是必须的吗?未必。这么多typedef完全是拜C++的静态类型系统所赐。我不是说静态类型不好,事实上关于静态类型和动态类型历来都是学术界和工业界乐此不疲的热门口水战。我想说明的是, 有时候你想要舞蹈的时候,要低头看看,你的脚上是否带着不必要的镣铐。 C++的静态类型系统对于泛型编程而言,就是这样的镣铐。
-
C++模板的本质在于用编程的手段显式地控制编译器的代码生成。没错,聪明的你已经想到,Lisp的macro做的也是同样的事情。但是不同于Lisp的macro,由于C++模板的先天不足和C++静态类型系统的限制,C++在语言层面上对模板编程的支持非常有限。荣耀先生有一篇非常精炼的PPT《C++模板元编程技术与应用》, 基本上概括了C++模板编程的核心机制和语言实现,我摘录了一些如下:
- 引用、指针、const、static等:除了以上比较“重口味”的C++语言特性,C++里还有各种各样的语言小尾巴,而且这个尾巴一般都拉的特别长。当然,尾巴长的好处之一就是可以养活很多语言专家,什么effective啊、exceptional啊、faq啊啥的,在所有的编程语言中,C++这点绝对是独树一帜。其实每个语言特性的背后都有值得深究的知识, 没有任何事情是想当然的。14 const够简单了吧?可是你知道const pointer和pointer to const的区别吗?你知道什么时候用const引用传参什么时候返回const引用什么时候返回值吗?你知道const成员函数吗?你知道为什么会有初始化成员列表的存在吗?再来说说引用这个概念,其本质上就是一种受限指针加上编译器层面上的语法糖修饰,按理说不太难,但是什么时候传引用返回引用确是值得深究的好问题,搞清楚了这点,你就会搞明白C++中的copy constructor/copy assignment operator,Java中的Object.clone(),Python中的"is"、和Lisp中的eq/eql/equal。传引用/指针还是传值涉及到深刻的程序语言原理,并不是你想象的那么简单而已。
- 以上谈了这么多,读者可能会问,既然C++如此繁杂,还要不要学习C++?学,当然要学,否则你怎么批判呢?怎么学?批判地学。要去学习语言机制的根源和本质而不要迷失在语言特性的森林里15。
- 最后,还是回到面试题上,还是放上鄙人的C++代码,也好和Lisp/Python版的程序做一个小对比:
#include <queue>
#include <limits>
#include <iostream>
#include <vector>
#include <map>
#include <functional>
#include <queue>
#include <list>
#include <cstdlib>
using namespace std;
struct vertex
{
int index; /// the vertex index, also the vertex name
vertex* prev; /// the prev vertex node computed by bfs and bfs_shortest
int dist; /// the distance to the start computed by bfs
/// and bfs_shortest
vector<vertex*> adj; /// the adjacency list for this vertex
vertex(int idx)
: index(idx) {
reset();
}
void reset() {
prev = NULL;
dist = numeric_limits<int>::max();
}
};
class graph
{
public:
graph() { }
~graph();
void add_edge(int start, int end);
void bfs(int start);
void bfs_shortest(int start);
list<int> get_path(int end) const;
void print_graph() const;
protected:
vertex* get_vertex(int idx);
void reset_all();
list<int> get_path(const vertex &end) const;
private:
/// disable copy
graph(const graph &rhs);
graph& operator=(const graph &rhs);
typedef map<int, vertex*, less<int> > vmap;
vmap vm;
};
graph::~graph() {
for (vmap::iterator itr = vm.begin(); itr != vm.end(); ++itr)
{
delete (*itr).second;
}
}
/**
* return a new vertex if not exists, else return the old vertex, using std::map
* for vertex management
*
* @param idx vertex index
*
* @return a (new) vertex of index idx
*/
vertex* graph::get_vertex(int idx) {
/// cout << "idx: " << idx << "\tvm.size(): " << vm.size() << endl;
vmap::iterator itr = vm.find(idx);
if (itr == vm.end())
{
vm[idx] = new vertex(idx);
return vm[idx];
}
return itr->second;
}
/**
* clear all vertex state flags
*
*/
void graph::reset_all() {
for (vmap::iterator itr = vm.begin(); itr != vm.end(); ++itr)
{
(*itr).second->reset();
}
}
/**
* add an edge(start --> end) to the graph
*
* @param start
* @param end
*/
void graph::add_edge(int start, int end) {
vertex *s = get_vertex(start);
vertex *e = get_vertex(end);
s->adj.push_back(e);
}
/**
* print the graph vertex by vertex(with adj list)
*
*/
void graph::print_graph() const {
for (vmap::const_iterator itr = vm.begin(); itr != vm.end(); ++itr)
{
cout << itr->first << ": ";
for (vector<vertex*>::const_iterator vitr = itr->second->adj.begin();
vitr != itr->second->adj.end();
++vitr)
{
cout << (*vitr)->index << " ";
}
cout << endl;
}
}
/**
* traversal the graph breadth-first
*
* @param start the starting point of the bfs traversal
*/
void graph::bfs(int start) {
if (vm.find(start) == vm.end())
{
cerr << "graph::bfs(): invalid point index " << start << endl;
return;
}
vertex *s = vm[start];
queue<vertex*> q;
q.push(s);
s->dist = -1;
while (!q.empty()) {
vertex *v = q.front();
cout << v->index << " ";
q.pop();
for (int i = 0; i < v->adj.size(); ++i)
{
if (v->adj[i]->dist != -1)
{
q.push(v->adj[i]);
v->adj[i]->dist = -1;
}
}
}
}
/**
* the unweighted shortest path algorithm, using a std::queue instead of
* priority_queue(which is used in dijkstra's algorithm)
*
* @param start
*/
void graph::bfs_shortest(int start) {
if (vm.find(start) == vm.end())
{
cerr << "graph::bfs_shortest(): invalid point index " << start << endl;
return;
}
vertex *s = vm[start];
queue<vertex*> q;
q.push(s);
s->dist = 0;
while (!q.empty()) {
vertex *v = q.front();
q.pop();
for (int i = 0; i < v->adj.size(); ++i)
{
vertex *w = v->adj[i];
if (w->dist == numeric_limits<int>::max())
{
w->dist = v->dist + 1;
w->prev = v;
q.push(w);
}
}
}
}
/**
* get the path from start to end
*
* @param end
*
* @return a list of vertex which denotes the shortest path
*/
list<int> graph::get_path(int end) const {
vmap::const_iterator itr = vm.find(end);
if (itr == vm.end())
{
cerr << "graph::get_path(): invalid point index " << end << endl;
return list<int>();
}
const vertex &w = *(*itr).second;
if (w.dist == numeric_limits<int>::max())
{
cout << "vertex " << w.index << " is not reachable";
return list<int>();
}
else {
return get_path(w);
}
}
/**
* the internal helper function for the public get_path function
*
* @param end
*
* @return a list of vertex index
*/
list<int> graph::get_path(const vertex &end) const {
list<int> l;
const vertex *v = &end;
while (v != NULL) {
l.push_front(v->index);
v = v->prev;
}
return l;
}
class chessboard {
private:
struct point {
int x;
int y;
point(int px, int pb)
: x(px), y(pb) { }
};
public:
chessboard(int s);
void solve_knight(int x, int y);
protected:
bool is_valid(const point &p);
point next_point(const point &p, int i);
private:
graph board;
int size;
};
/**
* constructor, build a underlying graph from a chessboard of size s
*
* @param s
*/
chessboard::chessboard(int s)
: size(s) {
for (int i = 0; i < size; ++i)
{
for (int j = 0; j < size; ++j)
{
int start = i * size + j;
point p(i, j);
for (int k = 0; k < 8; ++k)
{
/// the next possible knight position
point np = next_point(p, k);
if (is_valid(np))
{
int end = np.x * size + np.y;
/// add edges in both directions
board.add_edge(start, end);
board.add_edge(end, start);
}
}
}
}
}
/**
* find and print a path from (x, y) to (size, size)
*
* @param x
* @param y
*/
void chessboard::solve_knight(int x, int y) {
int start = (x-1) * size + (y-1);
int end = size * size - 1;
board.bfs_shortest(start);
list<int> l = board.get_path(end);
int count = 0;
for (list<int>::const_iterator itr = l.begin(); itr != l.end(); ++itr)
{
cout << "(" << *itr/size + 1 << ", " << *itr%size + 1<< ")";
if (count++ != l.size() - 1)
{
cout << " -> ";
}
}
cout << endl;
}
/**
* whether or not the point is valid in the chessboard
*
* @param p
*
* @return true for valid
*/
bool chessboard::is_valid(const point &p) {
if (p.x < 0 || p.x >= size - 1 || p.y < 0 || p.y >= size - 1)
{
return false;
}
return true;
}
/**
* the next possible position, every has 8 next possible position, though not
* all 8 position is valid
*
* @param p the original knight position
* @param i
*
* @return
*/
chessboard::point chessboard::next_point(const point &p, int i) {
int knight[8][2] = {
{2, 1}, {2, -1},
{-2, 1}, {-2, -1},
{1, 2}, {1, -2},
{-1, 2}, {-1, -2}
};
return point(p.x + knight[i][0], p.y + knight[i][1]);
}
int main(int argc, char *argv[])
{
if (argc != 4)
{
cerr << "Wrong arguments! Usage: knight.bin N x y" << endl;
return -1;
}
int N = atoi(argv[1]);
int x = atoi(argv[2]);
int y = atoi(argv[3]);
chessboard chess(N);
chess.solve_knight(x, y);
return 0;
}
4 Lisp
Lisp是一门阳春白雪的语言,前两天我去面试一个linux后端开发的职位,面试官看到我的简历还当面问我“Lisp是一个什么东西”……Lisp最广为人知的特点,大概就是——括号了吧。因此Lisp除了代表"List Processing", 还有一个别名"Lots of Irritating Superfluous Parentheses"。括号的背后其实是S-expression。诈看上去,S-expression (+ 1 2)比之于我们熟悉的"1 + 2"确实要晦涩一点,但是你要明白的是,我们之所以比较喜欢"1 + 2"这种形式的写法,那完全是我们小学教育的错16。想想高等数学吧,函数f(x, y, z),翻译成Lisp的S-expression就是(f x y z),但是如何翻译成"1 + 2"形式的语句呢?事实上在Lisp发明之初,确实有人指出说S-expression写起来特别的别扭,John McCarthy也曾经试图将S-expression转换成M-expression 的形式,可是后来人们发现S-expression所带来的好处远远超出其微末的学习成本,M-expression的计划也就无疾而终了。S-expression是Lisp程序员一切欢乐与痛苦的来源17。
- S-expression带给Lisp的第一个好处是语法的简单一致性。显而易见的例子就是Lisp中没有类似于C语言中的运算符优先表。
- S-expression带给Lisp的第二个好处是Homoiconicity, 体现在Lisp中,就是"code is data"18。
-
基于"code is data", S-expreesion带给Lisp的第三个好处就是强大的macro。前面我们曾经讲到,“C++模板的本质在于用编程的手段显式地控制编译器的代码生成“,也就是所谓的元编程meta-programming。 我们还提到,C++在语言层面上对meta-programming的支持非常匮乏,因此才会有各种各样的workarounds(effective/exceptional中称为idioms或者techniques)。与C++模板不同,Lisp的macro可以调用几乎所有Lisp的语言机制。正式由于S-expression的存在,使得Lisp代码本身不经解析就是一颗完美的对编译器极度友好的抽象语法树, 当我们写Lisp macro的时候,我们其实是在和Lisp编译器交谈 ,我们告诉Lisp编译器,那些参数需要求值19,那些代码需要循环执行(do/dolist/dotimes),那些结构需要定义getter/setter(defstruct)等等。要知道,Lisp的老本行就是List Processing,而任何合法的Lisp的代码本身也一个List,用Lisp的能力来操作自身的代码,进行代码变换,这就是Lisp的macro。
- 好学的读者可能会问,元编程到底有什么用?其实很简单,当你在写一句句C语言代码的时候,你就已经在用元编程了。广义上来讲,任何能够控制代码生成的编程方法都可以看作是元编程,元编程其实是编译器的主要工作职能。不明白?好吧。我们要从遥远的汇编时代讲起。没有C语言(高级语言)之前,人们在汇编语言的酱缸中浸淫。终于有一天,有那么几位智者大神跳出来,总结出说编程语言的控制结构无非就是顺序/选择/循环三种,于是就有了if,有了for/while,从此程序员就快乐写写if/for,抛弃了汇编,因为有一个叫做编译器的助手可以自动生成if/for的底层汇编代码。如果说编程是为了解决重复性的工作,那么元编程就是为了解决重复性的编程代码工作。
- Lisp的macro所带来的元编程能力与其他语言相比,其最大的特点在于Lisp的macro元编程是可扩展的,也就是说,我们可以通过Lisp的macro写一些库,而这些库和语言本身的机制能够很好的融合在一起;其余的语言诸如C++/Java,其语言机制的扩展则需要进行漫长的标准化进程。
除了以上,Lisp还有一些非常独特的优点,使得这么古老的阳春白雪般的语言虽然尚未蓬勃,但注定不会消亡:
- 快速反馈的交互式开发模型。是的,谈到Lisp开发就不能不谈到Emacs+Slime这套革命性的开发环境,没有Slime的Lisp,就像没有武器的战士一样。不同于C++的先构建再运行的开发模型,Lisp的开发模型是交互式的。你写了一个defun一个defstruct,不需要去main函数中写一段测试代码和print语句,然后编译运行看看结果是否符合预期;在Slime+Lisp的开发环境中,写了一个defun,C-c C-c即可编译完成,C-x C-e即可执行当前的一个表达式,快速的反馈和修改能够最大程度上保证你思维的连续性。关于这点可以参考我写的走进Lisp的世界——兼谈Emacs下Lisp的开发环境(上)。
-
强烈的数学味,更高层次的抽象,专注于what而不是how。
- Paul Graham在The Roots of Lisp中写到"It's worth understanding what McCarthy discovered, not just as a landmark in the history of computers, but as a model for what programming is tending to become in our own time. It seems to me that there have been two really clean, consistent models of programming so far: the C model and the Lisp model. These two seem points of high ground, with swampy lowlands between them. As computers have grown more powerful, the new languages being developed have been moving steadily toward the Lisp model. A popular recipe for new programming languages in the past 20 years has been to take the C model of computing and add to it, piecemeal, parts taken from the Lisp model, like runtime typing and garbage collection."
- 按照我的理解,我们可以对中文“计算机”这个词语做一次咬文嚼字的分拆,Lisp代表着“计算”,而C语言则代表“机”。
- Lisp具有强烈的数学色彩,Lisp程序中大量使用递归,深刻理解递归几乎是Lisp程序员的必备生存技能20。而C语言则终点关注底层机器模型,short/int/long/long long,不同数据类型的区分,榨干机器的内存空间;大量使用指针,将完整的冯诺依曼机器模型暴露给程序员,榨干机器的整体性能。
-
在Lisp中更加强调what you want,而C中则更加倾向于给出长长的算法步骤和状态变换指令,专注于how to get it。
- 比如求一个list的长度,在Lisp中,其核心代码就是(+ 1 (lenght (cdr lst)));而在C中,恐怕要设置int i = 0和各种计数器了21。
-
强类型的动态语言,一致的语法规则,关注实现域而非问题域,摒弃编程中的心智包袱。
- C++是一门有心智包袱的语言22,在C++编程中,我们常常要考虑诸如是传值还是传引用、要不要进行运算符重载、深拷贝还是浅拷贝、堆内存还是栈内存等等这些实现域而非问题域的语言细节问题。我不是说关注实现域这点不好,只是不能太过,而C++的讨厌之处就在于,为了所谓一点点的性能提升,经常性地将苦命的码农们从问题域拉回实现域。
-
万能的List,快速的原型构建能力。
- 如何用可递归的List来一体化的表达常见的数据结构,这个问题比较深刻,后续我会再写一篇文章深入探讨下。
本节的最后,还是给出完整的Lisp程序,核心代码只有70行左右,大概是C++的三分之一左右。主题算法和代码来自于《ANSI Common Lisp》3.15节。顺带广告,《ANSI Common Lisp》是非常不错的Common Lisp书籍(用来入门的话还是比较难啃的),300页不到的篇幅里基本上覆盖了Common Lisp大部分的语言特性,并且有很多极具实用价值的小程序(最短路、行程压缩编码、二叉树、二分搜索、光线跟踪算法等等)。我认为此书之于Lisp,相当于K&R C之于C。
(defun point2index (x y n)
"convert a coordinate point to an index"
(+ (* x n) y))
(defun index2chess (index n)
"convert an index back to a coordinate point"
(floor index n))
(defun build-graph (n)
"build a undirected unweighted graph according to the chess rules about
knight"
;; use lisp array to keep the vertex map
(let ((vm (make-array (* n n) :initial-element nil)))
;;; define some auxiliary function
(defun is-valid (x y)
"whether or not the point is valid in the chess board"
(and (>= x 0) (< x n)
(>= y 0) (< y n)))
(defun all-adj-points (x y)
"build the adjacency list for point (x, y)"
(let ((adj-list))
;; return every possible next knight position as a list
(dolist (next-step
'((2 . -1) (2 . 1)
(-2 . -1) (-2 . 1)
(1 . -2) (1 . 2)
(-1 . -2) (-1 . 2)))
(let ((nx (+ x (car next-step)))
(ny (+ y (cdr next-step))))
(if (is-valid nx ny)
;; build the adjacency list
(push (point2index nx ny n) adj-list))))
adj-list))
(dotimes (i n)
(dotimes (j n)
(setf (aref vm (point2index i j n)) (all-adj-points i j))))
vm))
(defun shortest-path (start end graph)
"one-source unweighted shortest-path algorithm using bfs method"
(bfs end (list (list start)) graph))
(defun bfs (end queue graph)
"the internal bfs routine to find shortest path"
(if (null queue)
nil
(let* ((path (car queue))
(node (car path)))
(if (eql node end)
(reverse path)
(bfs end
;; pop the queue and push some new path into the queue
(append (cdr queue)
(new-paths path node graph))
graph)))))
(defun new-paths (path node graph)
"return the new-paths according to the node's adj list"
(mapcar #'(lambda (n)
(cons n path))
(cdr (aref graph node))))
(defun solve-knight (n x y)
"the main function to solve knight problem"
(let ((path (shortest-path (point2index (- x 1) (- y 1) n)
(point2index (- n 1) (- n 1) n)
(build-graph n))))
;; print the start point first
(multiple-value-bind (x1 y1)
(index2point (car path) n)
(format t "(~A, ~A)" (+ x1 1) (+ y1 1)))
;; print the path
(mapcar #'(lambda (obj)
(multiple-value-bind (px py)
(index2point obj n)
(format t " -> (~A, ~A)"
(+ px 1)
(+ py 1))))
(cdr path))
;; return the path
path))
;;; some test
;; CL-USER> (SOLVE-KNIGHT 6 1 1)
;; (1, 1) -> (3, 2) -> (4, 4) -> (5, 6) -> (6, 4) -> (4, 5) -> (6, 6)
;; (0 13 21 29 33 22 35)
;; CL-USER> (SOLVE-KNIGHT 8 1 1)
;; (1, 1) -> (3, 2) -> (4, 4) -> (5, 6) -> (6, 8) -> (7, 6) -> (8, 8)
;; (0 17 27 37 47 53 63)
;; CL-USER> (SOLVE-KNIGHT 8 2 1)
;; (2, 1) -> (3, 3) -> (4, 5) -> (5, 7) -> (7, 6) -> (8, 8)
;; (8 18 28 38 53 63)
5 Python
坦白地说,我对Python的了解远不如C/C++,甚至不如Lisp,尽管我也用Python写过一些不大不小的原型程序,但是这些程序都没有触及到Python的语言核心。前两天写这个knight rush的程序,还要去翻书,熟悉下Python OOP编程的一些知识。我以为,Python是一门实用主义至上的语言,在保证实用主义的前提下,Python从诸多语言中吸收了很多特性,并一一做了精简(Python的OOP甚至没有private,而Python lambda对比Lisp算很一般),再加上简单至上的文化和缩进式的代码风格,构成了当今Python语言的主要面貌。
即便如此,我认为Python还是值得学习的。它既不像C/C++那样令人紧张、也不像Lisp那样阳春白雪,对比Shell Script,Python有自己的内建数据结构,能够在很大程度上替换Shell Script。其实和Python同级的语言还是有很多的,比如Perl,Ruby。Ruby我不了解,但是我对Perl/PHP/Shell这类遍布'$'符号的语言一向没什么好感,因为这类语言的可读性一般都很差。
其实关于Python本身,我已经没有太多想法可写,可能一方面我对Python的了解实在算不上深入,另一方面,Python本身也是不希望它的使用者过多关注于语言本身吧。对于Python,简单了解后拿过来直接用就好了,什么代码风格、缩进啊,那都是过去时的事情了。
作为对比,还是贴出Python版的Knight rush程序:
#!/usr/bin/env python2
import sys
class graph(object):
"""unweighted directed graph
"""
def __init__(self):
"""set _vmap to and _vprev an empty python dict
all vertex are represented by a simple index
_vmap: {vertex x: x's adjacency list}
_vprev: {vertex x: x's prev vertex computed by bfs routine}
"""
self._vmap = {};
self._vprev = {};
def add_edge(self, start, end):
"""add an edge to the graph
"""
if self._vmap.has_key(start):
self._vmap[start].append(end)
else:
self._vmap[start] = [end]
def bfs_shortest(self, start):
"""one-source shortest-path algorithm
"""
queue = [start]
self._vprev[start] = None
while len(queue) != 0:
v = queue[0]
queue.pop(0)
if self._vmap.has_key(v):
v_adj = self._vmap[v]
else:
continue
for nextv in v_adj:
if self._vprev.has_key(nextv):# and self._vprev[nextv] is not None:
# nextv has already found its parent""
continue
else:
queue.append(nextv)
self._vprev[nextv] = v
def get_path(self, end):
"""return the shortest path as a python list
"""
v = end;
path = []
while self._vprev.has_key(v) and self._vprev[v] is not None:
path.insert(0, v)
v = self._vprev[v]
if self._vprev.has_key(v):
path.insert(0, v) # insert the start point to the path
else:
print "destination %d is not exist or unreachable" % v
return path
class chessboard(object):
"""a chessboard of size n*n class
"""
def __init__(self, n):
"""build the internal graph representation of the chessboard
Arguments:
- `n`: size of the chessboard
"""
self._size = n
self._board = graph()
next_point = ((2, 1), (2, -1), \
(1, 2), (1, -2), \
(-2, 1), (-2, -1), \
(-1, 2), (-1, -2))
for x in range(n):
for y in range(n):
start = self.point2index(x, y)
for dx, dy in next_point:
nx = x + dx
ny = y + dy
if self.is_valid(nx, ny):
end = self.point2index(nx, ny)
self._board.add_edge(start, end)
def is_valid(self, x, y):
"""whether or not point (x, y) is valid in the chessboard
"""
return 0 <= x < self._size and 0 <= y < self._size
def point2index(self, x, y):
"""convert a chessboard point to the internal graph vertex index
"""
return x * self._size + y
def index2point(self, p):
"""convert the internal graph vertex index back to a chessboard point
"""
return (p / self._size, p % self._size)
def solve_knight(self, x, y):
"""just solve it
"""
start = self.point2index(x, y)
end = self.point2index(self._size - 1, self._size - 1)
self._board.bfs_shortest(start)
path = [self.index2point(x) for x in self._board.get_path(end)]
return [(x + 1, y + 1) for x, y in path]
def main():
"""main routine
"""
# g = graph()
# g.add_edge(1, 2)
# g.add_edge(1, 3)
# g.add_edge(2, 3)
# g.add_edge(3, 4)
# g.bfs_shortest(1)
# print g.get_path(4)
if len(sys.argv) != 4:
print """Wrong arguments! Usage: ./knight.py N x y
"""
return -1
N = int(sys.argv[1])
x = int(sys.argv[2])
y = int(sys.argv[3])
chess = chessboard(N)
print chess.solve_knight(x - 1, y - 1)
return 0
if __name__ == "__main__":
main()
# some test data
# $ ./knight.py 6 2 2
# [(2, 2), (4, 3), (6, 4), (4, 5), (6, 6)]
# $ ./knight.py 6 2 2
# [(2, 2), (4, 3), (6, 4), (4, 5), (6, 6)]
# $ ./knight.py 4 2 2
# [(2, 2), (4, 3), (2, 4), (3, 2), (4, 4)]
# $ ./knight.py 4 1 1
# [(1, 1), (3, 2), (4, 4)]
# $ ./knight.py 4 2 3
# [(2, 3), (4, 4)]
# $ ./knight.py 20 2 3
# [(2, 3), (4, 4), (6, 5), (8, 6), (10, 7), (12, 8), (14, 9), (16, 10), (18, 11), (20, 12), (19, 14), (20, 16), (19, 18), (20, 20)]
# $
6 总结
本文的初衷只是想针对此次面试做一个小的总结,但是写到一半发现面试题本身可写的内容不多,于是我就顺便写写我个人对C++/Lisp/Python的一些思考,而题目本身就“很悲剧地”成了本文的一个引子。写作终究不是一件容易的事情,将自己心中的想法转化成纸上清晰易懂的文字是一件耗时耗力的体力脑力并重的工作。整篇文章的写作大概耗时12个小时,但是写作的过程中也让我梳理了下自己的知识体系,如未鹏所言,“书写是为了更好的思考”。
罗嗦了这么多,其核心观点只有一个,那就是“ 要学会跳出语言的框架去学习语言 ”。站得高才能看得远, 只有跳出语言的框架,才能挣断语言给你的思维所上的枷锁,超越语言本身 ,看到更广阔的图景23。
–
Footnotes:
1 由于面试前后并没有保密协议,加上本文内容主要是以我个人的一些技术思考为主,因此题 目内容本引述邮件。如果违反相关招聘规定,请不吝告知,谢谢。
2 按照ACM的标准,我这样的编码速度估计是死定了。
3 其实我也不会,相信我,我只是在吹牛而已 ^_^ 。
4 四个程序员的一天, 一篇非常生动的高 阶函数科普小品文。
5 关于lambda函数的递归问题涉及到非常深刻的计算理论问题,其入门文章可以参考未鹏写的 康托尔、哥德尔、图灵——永恒的金色对角线, 围绕此话题有一本奇书 《哥德尔·艾舍尔·巴赫——集异璧之大成》, 曾长期绝版,最近当当有售,大家抓紧机会。
6 没错,STL和OO的数据封装思想几乎是背道而驰的。
7 Python中有Lisp Comprehension和类似于Lisp的map/reduce/filter套装。
8 boost function提供了更好的function object支持。
9 刘未鹏:泛型编程:源起、 实现与意义
10 关于C++语言特性的书籍简直可以用浩如烟海来形容,参看 这里、 这里。
11 关于这个IfThenElse模板,可以参考《C++ Templates》第15章的讲解与实现。
12 前文提到,C++模板代码是由C++编译器在编译期“解释执行”的,其冗长的编译时间、巨大的 编译资源以及内存资源需求,使得最新的GCC/Clang系列编译器对模板的递归层次支持也仅 有几千层而已。事实上编译时间的冗长也一直是C++模板被人诟病的地方之一。
13 看看《C++ Templates》Part 2吧,绝对 是顶级脑细胞杀手。
14 即便是int x = 3这样简单的一条赋值语句也不是你想象中的那么简单,看看 《SICP》 第三章吧。能够对变量直接赋 值是不同编程范式的一个主要区别,而这又从一个很重要的角度上决定了并行计算的本质困 难性。
15 怎么学?学习C++:实践者的 方法(Beta1)。
16 就好比我们喜欢十进制而非二进制,完全是因为上帝赐予了我们十根手指。
17 你也可以说,指针是C程序员一切欢乐与痛苦的来源。其实我想说的是,每种编程语言的核 心关注点不同,在此至上,语言本身会围绕着这个核心点发展出自己的一套设计哲学,然后 根据这套哲学来指导语言本身的设计和发展。
18 "Data is just dumb code, and code is just smart data",关于"code is data"的话题 涉及到计算机科学里面很多深刻的论题。比如说c程序中的.text段和.data段, 冯诺依曼体系结构和 哈佛体系结构, 编译器代码 生成等等。 Code is data, and it always has been。
19 学习Lisp带给你的一个思想革新就是,一个对象和这个对象的值是完全不同的东西(eval (quote x))。这是个很重要的概念,但这个概念在其余语言中往往是混为一体的,至少在语 法上是这样的。最简单的例子,比如c中的语句:x = x,等式的右边是x的值而不是x本身, 等式的左边是x本身而不是x的值,理解了这点,你就能理解C++中左值和右值的概念区别。 如果有机会,我会专门写篇文章,探讨下这个主题。
20 Lisp编程中的递归主要是数学归纳法的一种程式化转换, 《Common Lisp, A Gentle Introduction to Symbolic Computation》8.11节里面详细介绍了Lisp中递归的几种模式,清晰易懂, 强烈推荐。
21 这么简单的例子也许并不足以体现出Lisp和C这两种语言不同思维模式的区别,事实上如果 读者不去稍微深入地学习下Lisp的话,是很难体会到这种思维转变的。
22 具体可以参考孟岩先生的两篇文章, 用C设计,用C++编码 和 Linux之父话糙理不糙。
23 最后一个脚注(貌似我最近写文章脚注用得越来越多了,不知道这算是旁征博引还是逻辑不 清):侃侃那些美丽 的编程语言, ^_^ 。
zoj 1284
简单题。题目大意就是判断一个数是否为Perfect number。可是我竟然三次才ac,原因是没有考虑到数字为1的时候。
求真因数和的时候可以考虑质数判断的算法,循环到[tex]\sqrt{n}[/tex]就行了。代码很长很菜:
#include <stdio.h>
#include <math.h>
int get_sum(int number)
{
int i;
int sum = 0;
for (i = 1; i < sqrt(number); ++i)
{
if (number % i == 0)
{
sum += i + number / i;
}
}
if ((int)sqrt(number) * (int)sqrt(number) == number)
{
sum += sqrt(number);
}
sum -= number;
return sum;
}
int main(int argc, char *argv[])
{
int number;
printf ("PERFECTION OUTPUT\n");
while (scanf("%d", &number) && number)
{
int sum = get_sum(number);
if (sum < number)
{
printf ("%5.0d DEFICIENT\n", number);
}
else if (sum == number)
{
printf ("%5.0d PERFECT\n", number);
}
else
printf ("%5.0d ABUNDANT\n", number);
}
printf ("END OF OUTPUT\n");
return 0;
}
zoj 1168
模拟递归问题。直接递归肯定不行,最容易想到的方法就是用数组模拟。中途遇到了一个问题,就是c++ iostream库的效率问题。用cin >> a >> b >> c时,TLE;换成scanf("%d%d%d", &a, &b, &c)时,AC,时间80ms。status中最前面的都是60ms,看来优化空间不大。关于c库和c++库的输入输出,还有待研
/**
* @file zoj1168.c
* @author <lox@freelox>
* @date Wed May 19 18:59:59 2010
*
* @brief zoj1168, 模拟问题。直接查表解决。
* 但是需要注意的是,此题目用scanf系列,AC,时间80ms,用c++的cin流,则TLE,
* 莫非cin和scanf真有那么大的时间消耗差别?
*/
#include <stdio.h>
int main(int argc, char *argv[])
{
int w[21][21][21];
int a, b, c;
for (a = 0; a <= 20; a++)
{
for (b = 0; b <= 20; b++)
{
for (c = 0; c <= 20; c++)
{
if (a == 0 || b == 0 || c == 0)
{
w[a][b][c] = 1;
}
else if (a < b && b < c)
{
w[a][b][c] = w[a][b][c-1] + w[a][b-1][c-1] - w[a][b-1][c];
}
else
w[a][b][c] = w[a-1][b][c] + w[a-1][b-1][c] + w[a-1][b][c-1] - w[a-1][b-1][c-1];
}
}
}
while (scanf("%d%d%d", &a, &b, &c))
{
if (a == -1 && b == -1 && c == -1)
{
return 0;
}
if (a <= 0 || b <= 0 || c <= 0)
{
printf("w(%d, %d, %d) = %d\n",a,b,c,w[0][0][0]);
}
else if (a > 20 || b > 20 || c > 20)
{
printf("w(%d, %d, %d) = %d\n",a,b,c,w[20][20][20]);
}
else
printf("w(%d, %d, %d) = %d\n",a,b,c,w[a][b][c]);
}
return 0;
}
bst, avl, c++, inheritance, template, two days
鉴于大二上年幼无知加上某些特殊的原因,导致我大三才开始修读高级数据结构。同一屋子大二的小朋友们上课,百般滋味,心中自知。第一次课迟到了,下课的时候随便找了两个学弟,算是组了个队,并申请做Project1(因为开始的Project)会比较简单。
实践起来也不是很难,就是让你比较下BinarySearchTree, AVL Tree和Splay Tree的插入删除效率的问题。两个学弟看样子都不愿意编码,于是乎,编码的重担就落在了我这个学长身上。可是只有我自己知道,我数据结构学的实在不咋的,C++又是个半吊子。唉,谁让咱是学长呢?
学长嘛,自然要有个学长的样子。于是乎,C++、Template、Inheritance、Polymorphism,能用上的都用上……呵呵。不过主要是想练一下手。C++ Primer虽然看了大半,却没有多少应用的机会。这也算是一个练习吧。
写着写着就知道,C++的强大是一把双刃剑,强大到你无法驾驭,尤其是应用了模板后,各种小问题,都是以前闻所未闻的。比如模板的分离编译问题,看书,查资料就花了两个小时。加上昨天下午吐血恶心的同步时序电路的逻辑实验,做的我都想哭了。所以这么看上去很简单的project,我竟然写了接近两天,倍感惭愧。
不过总算出来了。但是有个瑕疵,avl的删除功能有些小问题,可能跟Balance函数和指针的引用问题有关。gdb我用的不熟,转到强大的windows下的visual studio 2008下,调试了3个小时,找到错误所在,但是却不知道怎么改正。泪奔。
计算几何最终还是低空坠毁,唉,不提也罢,看来以后不能乱选课,选了课不能随便混混。混不好就低空坠毁。你说你没事选这么一门前沿课程干嘛,你是这块料嘛……
计算几何过后开始准备计算理论的期中考试。什么有穷自动机,正则语言,上下文无关文法,等等,计算理论基础的中文版,每个小时3页,龟速前进,发现还是太抽象,看不大懂,又找来一本计算理论导引,两本结合着看,顿觉顺畅很多,看来计算机的书还是要原汁原味的英文啊。
感觉计算理论期中还不错。周一被导师叫去公司,让我参加项目,大意是让我写一个TextArea。项目代码有四万左右,光理清这个体系,补windows编程的基础知识就花了我三四天的时间。终于搞明白了什么叫windows ce,什么叫GDI,学会了windows下svn的基本用法。可是看windows ce的书还是一头雾水,什么HINSTANCE,WINAPI WinMain(),叉叉的。基本流程我还不懂。于是去找windows经典书目的书单,看到多人推荐Charles Petzold的windows程序设计,吐血买了下来,花了150元。Microsoft的书真tn的贵。
不过书是好书。周六周日周一断续看了三天,看了四章,120页,顿时明白了很多。个人windows的技术更新太快,不想unix,二十年前的vim、emacs、grep,等,万古不变。掌握win32 API才是一切的根本。永远不要指望跟上Microsoft的脚步。
只不过到现在导师的项目还没有开工,我还夸下海口自不量力要一周写出来。这可如何是好。还有图形学作业,操作系统作业,实验的作业,呃……少壮不努力,老大做it,大二不学习,大三干苦力。要努力。恩。
BinarySearchTree.h:
#define _BINARYSEARCHTREE_H_
#include <iostream>
#include <stack>
using namespace std;
/// 三种遍历方式
#define PREORDERTRAVERSE 0
#define INORDERTRAVERSE 1
#define POSTORDERTRAVERSE 2
/// 求两个元素的最大值
#define max(x, y) ((x > y) ? (x) : y)
/**
* @class BinaryNode
* @brief 树的结点,为了方便BST和AVL用了同一种结构。BST中所有结点的height域为默认值
*/
template<typename Comparable>
struct BinaryNode
{
Comparable element;
BinaryNode* left;
BinaryNode* right;
int height;
BinaryNode(const Comparable &theElement, BinaryNode *lt, BinaryNode *rt, const int theHeight = 0)
: element(theElement), left(lt), right(rt), height(theHeight) {}
};
/**
* @class BinarySearchTree
* @brief 实现了常见的删除,插入功能。并作为AVL树的基类
*/
template<typename Comparable>
class BinarySearchTree
{
public:
BinarySearchTree();
~BinarySearchTree();
BinaryNode<Comparable>*& GetRoot();
void BuildBinaryTree(Comparable *x, int length);
const Comparable& FindMin() const;
const Comparable& FindMax() const;
bool Contains(const Comparable &x) const;
bool IsEmpty() const;
void TraverseTree(int type);
void MakeEmpty();
virtual void Insert(const Comparable &x);
virtual void Remove(const Comparable &x);
private:
BinaryNode<Comparable> *root;
virtual void Insert(const Comparable &x, BinaryNode<Comparable> *&t) const;
virtual void Remove(const Comparable &x, BinaryNode<Comparable> *&t) const;
BinaryNode<Comparable>* FindMin(BinaryNode<Comparable> *&t) const;
BinaryNode<Comparable>* FindMax(BinaryNode<Comparable> *&t) const;
bool Contains(const Comparable &x, BinaryNode<Comparable> *&t) const;
void MakeEmpty(BinaryNode<Comparable> *&t);
void PreOrderTraverse(BinaryNode<Comparable> *&t);
void InOrderTraverse(BinaryNode<Comparable> *&t);
void PostOrderTraverse(BinaryNode<Comparable> *&t);
};
/**
* 构造函数,默认root=NULL
*
*
* @return
*/
template<typename Comparable>
BinarySearchTree<Comparable>::BinarySearchTree() : root(NULL){}
/**
* 析构函数
*
*
* @return
*/
template<typename Comparable>
BinarySearchTree<Comparable>::~BinarySearchTree()
{
MakeEmpty();
}
/**
* 得到根节点的引用
*
*
* @return 返回根节点的引用
*/
template<typename Comparable>
BinaryNode<Comparable>*& BinarySearchTree<Comparable>::GetRoot()
{
return root;
}
/**
* 建立BST树,通过数组的方式传入元素,调用Insert(x)函数
*
* @param x
* @param length
*/
template<typename Comparable>
void BinarySearchTree<Comparable>::BuildBinaryTree(Comparable *x, int length)
{
for (int i = 0; i < length; ++i)
{
Insert(x[i]);
}
}
/**
* @return BST中的最小值
*/
template<typename Comparable>
const Comparable& BinarySearchTree<Comparable>::FindMin() const
{
return FindMin(root)->element;
}
/**
* @return BST中的最大值
*/
template<typename Comparable>
const Comparable& BinarySearchTree<Comparable>::FindMax() const
{
return FindMax(root)->element;
}
/**
* 测试x是否在BST中,调用私有函数Contains(x, root)
*
* @param x
*
* @return
*/
template<typename Comparable>
bool BinarySearchTree<Comparable>::Contains(const Comparable &x) const
{
return Contains(x, root);
}
/**
* 测试树是否为空
*
*
* @return
*/
template<typename Comparable>
bool BinarySearchTree<Comparable>::IsEmpty() const
{
if (root == NULL)
{
return true;
}
return false;
}
/**
* 以三种方式遍历树
*
* @param type 遍历树的方式
*/
template<typename Comparable>
void BinarySearchTree<Comparable>::TraverseTree(int type)
{
if (type == PREORDERTRAVERSE)
{
cout << "PreOrderTraverse the tree:" << endl;
PreOrderTraverse(root);
cout << endl << "PreOrderTraverse ends." << endl;
}
if (type == INORDERTRAVERSE)
{
cout << "InOrderTraverse the tree:" << endl;
InOrderTraverse(root);
cout << endl << "InOrderTraverse ends." << endl;
}
if (type == POSTORDERTRAVERSE)
{
cout << "PostOrderTraverse the tree:" << endl;
PostOrderTraverse(root);
cout << endl << "InOrderTraverse ends." << endl;
}
}
/**
* 清空BST树
*
*/
template<typename Comparable>
void BinarySearchTree<Comparable>::MakeEmpty()
{
MakeEmpty(root);
}
/**
* 向BST中插入一个元素
*
* @param x 待插入的元素
*/
template<typename Comparable>
void BinarySearchTree<Comparable>::Insert(const Comparable &x)
{
Insert(x, root);
}
/**
* 从BST中删除一个元素
*
* @param x 被删除的元素
*/
template<typename Comparable>
void BinarySearchTree<Comparable>::Remove(const Comparable &x)
{
Remove(x, root);
}
/**
* 向树根为t的树中插入一个元素
*
* @param x 待插入的元素
* @param t 树根
*/
template<typename Comparable>
void BinarySearchTree<Comparable>::Insert(const Comparable &x, BinaryNode<Comparable> *&t) const
{
if (t == NULL)
{
t = new BinaryNode<Comparable>(x, NULL, NULL, -3);
}
else if (x < t->element)
{
Insert(x, t->left);
}
else if (x > t->element)
{
Insert(x, t->right);
}
else
; //dupicate; you can do something, of course
}
/**
* 从树根为t的树中删除元素
*
* @param x 被删除的元素
* @param t 树根
*/
template<typename Comparable>
void BinarySearchTree<Comparable>::Remove(const Comparable &x, BinaryNode<Comparable> *&t) const
{
if (t == NULL)
{
return;
}
else if (x < t->element)
{
Remove(x, t->left);
}
else if (x > t->element)
{
Remove(x, t->right);
}
else if (t->left != NULL && t->right != NULL)
{
t->element = FindMin(t->right)->element;
Remove(t->element, t->right);
}
else
{
BinaryNode<Comparable> *oldNode = t;
t = (t->left != NULL) ? t->left : t->right;
delete oldNode;
}
}
template<typename Comparable>
BinaryNode<Comparable>* BinarySearchTree<Comparable>::FindMin(BinaryNode<Comparable> *&t) const
{
if (t != NULL)
{
while(t->left != NULL)
t = t->left;
}
return t;
}
template<typename Comparable>
BinaryNode<Comparable>* BinarySearchTree<Comparable>::FindMax(BinaryNode<Comparable> *&t) const
{
if (t != NULL)
{
while(t->right != NULL)
t = t->right;
}
return t;
}
template<typename Comparable>
bool BinarySearchTree<Comparable>::Contains(const Comparable &x, BinaryNode<Comparable> *&t) const
{
if (t == NULL)
{
return false;
}
else if (x < t->element)
{
return Contains(x, t->left);
}
else if (x > t->element)
{
return Contains(x, t->right);
}
else
return true;
}
template<typename Comparable>
void BinarySearchTree<Comparable>::MakeEmpty(BinaryNode<Comparable> *&t)
{
if (t != NULL)
{
MakeEmpty(t->left);
MakeEmpty(t->right);
delete t;
}
t = NULL;
}
/**
* 前序遍历
*
* @param t
*/
template<typename Comparable>
void BinarySearchTree<Comparable>::PreOrderTraverse(BinaryNode<Comparable> *&t)
{
if (t != NULL)
{
cout << t->element << " ";
PreOrderTraverse(t->left);
PreOrderTraverse(t->right);
}
}
/**
* 中序遍历
*
* @param t
*/
template<typename Comparable>
void BinarySearchTree<Comparable>::InOrderTraverse(BinaryNode<Comparable> *&t)
{
if (t != NULL)
{
InOrderTraverse(t->left);
cout << t->element << " ";
InOrderTraverse(t->right);
}
}
/**
* 后序遍历
*
* @param t
*/
template<typename Comparable>
void BinarySearchTree<Comparable>::PostOrderTraverse(BinaryNode<Comparable> *&t)
{
if (t != NULL)
{
PostOrderTraverse(t->left);
PostOrderTraverse(t->right);
cout << t->element << " ";
}
}
/**
* @class AVLTree
* @brief 由于AVLTree本身是一种改进的BST树,所以绝大多数特性继承自BST树。其中的Insert()和Remove方法和BST树中不同,因此在BST类中将此方法声明为virtual function
*/
template<typename Comparable>
class AVLTree : public BinarySearchTree<Comparable>
{
public:
AVLTree();
~AVLTree();
int GetHeight();
void Insert(const Comparable &x);
void Remove(const Comparable &x);
protected:
int GetHeight(BinaryNode<Comparable> *&t);
void Insert(const Comparable &x, BinaryNode<Comparable> *&t);
void Remove(const Comparable &x, BinaryNode<Comparable> *&t);
void SingleRotateLeftChild(BinaryNode<Comparable> *&k2);
void SingleRotateRightChild(BinaryNode<Comparable> *&k2);
void DoubleRotateLeftChild(BinaryNode<Comparable> *&k3);
void DoubleRotateRightChild(BinaryNode<Comparable> *&k3);
void Balance(BinaryNode<Comparable> *&t);
};
/**
* 构造函数,调用BST基类的构造函数
*
*
* @return
*/
template<typename Comparable>
AVLTree<Comparable>::AVLTree() : BinarySearchTree<Comparable>::BinarySearchTree()
{
// BinaryNode<Comparable>* root = BinarySearchTree<Comparable>::GetRoot();
// root = NULL;
}
/**
* 析构函数,调用基类的BST::MakeEmpty()
*
*
* @return
*/
template<typename Comparable>
AVLTree<Comparable>::~AVLTree()
{
BinarySearchTree<Comparable>::MakeEmpty();
}
/**
* 得到整棵AVL树的高度
*
*
* @return
*/
template<typename Comparable>
int AVLTree<Comparable>::GetHeight()
{
BinaryNode<Comparable>*& root = BinarySearchTree<Comparable>::GetRoot();
return GetHeight(root);
}
/**
* 向AVL中插入元素x
*
* @param x 待插入的元素
*/
template<typename Comparable>
void AVLTree<Comparable>::Insert(const Comparable &x)
{
BinaryNode<Comparable>*& root = BinarySearchTree<Comparable>::GetRoot();
Insert(x, root);
}
/**
* 从AVL中删除元素x
*
* @param x 被删除的元素
*/
template<typename Comparable>
void AVLTree<Comparable>::Remove(const Comparable &x)
{
BinaryNode<Comparable>*& root = BinarySearchTree<Comparable>::GetRoot();
Remove(x, root);
}
/**
* 得到结点t的高度
*
* @param t
*
* @return
*/
template<typename Comparable>
int AVLTree<Comparable>::GetHeight(BinaryNode<Comparable> *&t)
{
return t == NULL ? -1 : t->height;
}
template<typename Comparable>
void AVLTree<Comparable>::Insert(const Comparable &x, BinaryNode<Comparable> *&t)
{
if (t == NULL)
{
t = new BinaryNode<Comparable>(x, NULL, NULL);
}
else if (x < t->element)
{
Insert(x, t->left);
Balance(t);
// if (GetHeight(t->left) - GetHeight(t->right) == 2)
// {
// if (x < t->left->element)
// {
// SingleRotateLeftChild(t);
// }
// else
// DoubleRotateLeftChild(t);
// }
}
else if (x > t->element)
{
Insert(x, t->right);
Balance(t);
// if (GetHeight(t->right) - GetHeight(t->left) == 2)
// {
// if (t->right->element < x)
// {
// SingleRotateRightChild(t);
// }
// else
// DoubleRotateRightChild(t);
// }
}
else
;
t->height = max(GetHeight(t->left), GetHeight(t->right)) + 1;
}
/**
* 有个小bug,弄了一天也没弄出来,可能问题在Balance()和指针的引用上
*
* @param x
* @param t
*/
template<typename Comparable>
void AVLTree<Comparable>::Remove(const Comparable &x, BinaryNode<Comparable> *&t)
{
static stack<BinaryNode<Comparable>*> tStack;/// 定义一个静态堆栈,存储访问结点的路径
int tSize = tStack.size();/// 得到栈的大小
if (t == NULL)
{
return;
}
else if (x < t->element)
{
tStack.push(t);
cout << "traverse through " << t->element << endl;
Remove(x, t->left);
}
else if (x > t->element)
{
tStack.push(t);
cout << "traverse through " << t->element << endl;
Remove(x, t->right);
}
else if (t->left != NULL && t->right != NULL)
{
tStack.push(t);
cout << "traverse through " << t->element << endl;
BinaryNode<Comparable>*& oldT = t->right;
while (oldT->left != NULL)
{
tStack.push(oldT);
cout << "traverse through " << oldT->element << endl;
oldT = oldT->left;
}
t->element = oldT->element;
Remove(t->element, t->right);
}
else
{
BinaryNode<Comparable>*& oldNode = t;
t = (t->left != NULL) ? t->left : t->right;
delete oldNode;
}
BinaryNode<Comparable>* tempStack;
tSize = tStack.size(); /// 更新堆栈大小
for (int i = 0; i < tSize; i++)
{
tempStack = tStack.top();/// 回溯访问结点
Balance(tempStack);/// 对每个结点做Balance处理
tStack.pop();/// 已经做过Balance处理的结点出栈
}/// 此处可以进一步优化
return ;
}
template<typename Comparable>
void AVLTree<Comparable>::SingleRotateLeftChild(BinaryNode<Comparable> *&k2)
{
BinaryNode<Comparable> *k1 = k2->left;
k2->left = k1->right;
k1->right = k2;
k2->height = max(GetHeight(k2->left), GetHeight(k2->right)) + 1;
k1->height = max(GetHeight(k1->left), k2->height) + 1;
k2 = k1;
}
template<typename Comparable>
void AVLTree<Comparable>::SingleRotateRightChild(BinaryNode<Comparable> *&k1)
{
BinaryNode<Comparable> *k2 = k1->right;
k1->right = k2->left;
k2->left = k1;
k1->height = max(GetHeight(k1->left), GetHeight(k1->right)) + 1;
k2->height = max(k1->height, GetHeight(k2->right)) + 1;
k1 = k2;
}
template<typename Comparable>
void AVLTree<Comparable>::DoubleRotateLeftChild(BinaryNode<Comparable> *&k3)
{
SingleRotateRightChild(k3->left);
SingleRotateLeftChild(k3);
}
template<typename Comparable>
void AVLTree<Comparable>::DoubleRotateRightChild(BinaryNode<Comparable> *&k1)
{
SingleRotateLeftChild(k1->right);
SingleRotateRightChild(k1);
}
/**
* 计算t的平衡因子,分为四种不同情况分别调用不同函数处理
*
* @param t 树根
*/
template<typename Comparable>
void AVLTree<Comparable>::Balance(BinaryNode<Comparable> *&t)
{
if (GetHeight(t->left) - GetHeight(t->right) == 2)
{
if (GetHeight(t->left->left) > GetHeight(t->left->right))
{
SingleRotateLeftChild(t);
}
else if (GetHeight(t->left->left) < GetHeight(t->left->right))
{
DoubleRotateLeftChild(t);
}
else
;
}
if (GetHeight(t->left) - GetHeight(t->right) == -2)
{
if (GetHeight(t->right->right) > GetHeight(t->right->left))
{
SingleRotateRightChild(t);
}
else if (GetHeight(t->right->right) < GetHeight(t->right->left))
{
DoubleRotateRightChild(t);
}
else
;
}
}
#endif /* _BINARYSEARCHTREE_H_ */
main.cpp:
#include "BinarySearchTree.h"
using namespace std;
int main(int argc, char *argv[])
{
int a[10] = {5, 9, 10, 1, 3, 6, 4, 7, 8, 2};
AVLTree<int> avl;
avl.BuildBinaryTree(a, 10);
avl.Insert(11);
avl.TraverseTree(0);
avl.Remove(9);
avl.TraverseTree(0);
avl.Remove(10);
avl.TraverseTree(0);
return 0;
}
今天买了三本书
第一本:货币战争。
第二本:C++程序设计原理与实践。
第三本:Unix编程艺术。
共131.8元,花尽了钱包里的所有钱,一分不剩。印象中好像好久没有这样买过书了。尽管我的书已经不少了,多的连宿舍的书架都放不下了。
这一周整个人就像一部机器一样在运转。上周五开始做作业。先是完成了导师布置的任务——写一个iphone下的hello world程序。坦白的说,有些时候我是很随意的,有些时候又过于吹毛求疵。这么一个任务,我看了网上的数十篇文章,下载了十几篇pdf电子书,经过筛选总结最后写出了一份精美的带有目录,索引的达27页的英文文档。题目叫The Cross-Platform Developing Skills for Mac Applications给导师发了过去。可是导师实在是太忙了。没有时间看我的文档。只是今天中午交谈的时候看到文档,简介大气,还是称赞了一下,呵呵。
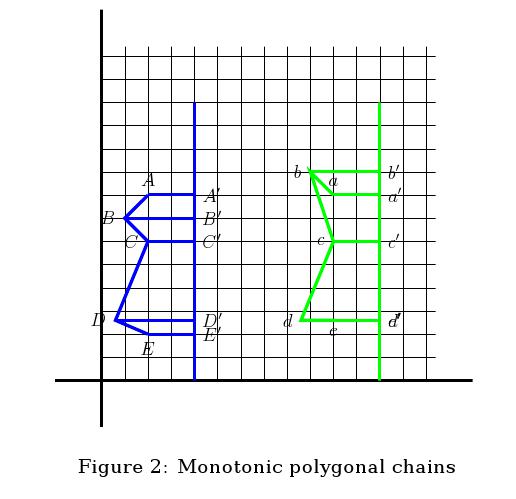
周日和周一都在补计算几何的知识,用的教材是Computational Geometry in C,刚开始还好,越到后来越难。布置的作业也都很有难度。导致我两天下来才做了十道题。虽然迟交了几天,但总算是弥补了。交总比不交好。交的作业是用latex写的。画一些几何图形,顺便学了学pfg\tikz的用法。真的很不错。如下面的代码:
\centering
\begin{tikzpicture}[line width=2pt]
\draw (-1,0) -- (8,0);
\draw (0,-1) -- (0,8);
\draw[step=.5cm, very thin] (0,0) grid (7.2,7.2);
\coordinate [label=above:$A$] (A) at (1, 4);
\coordinate [label=left:$B$] (B) at (0.5, 3.5);
\coordinate [label=left:$C$] (C) at (1, 3);
\coordinate [label=left:$D$] (D) at (0.3, 1.3);
\coordinate [label=below:$E$] (E) at (1, 1);
\draw[blue] (A) -- (B) -- (C) -- (D) -- (E);
\draw[blue] (2, 0) -- (2, 6);
\coordinate [label=right:$A'$] (A') at (2, 4);
\coordinate [label=right:$B'$] (B') at (2, 3.5);
\coordinate [label=right:$C'$] (C') at (2, 3);
\coordinate [label=right:$D'$] (D') at (2, 1.3);
\coordinate [label=right:$E'$] (E') at (2, 1);
\draw[blue] (A) -- (A');
\draw[blue] (B) -- (B');
\draw[blue] (C) -- (C');
\draw[blue] (D) -- (D');
\draw[blue] (E) -- (E');
\coordinate [label=above:$a$] (a) at (5, 4);
\coordinate [label=left:$b$] (b) at (4.5, 4.5);
\coordinate [label=left:$c$] (c) at (5, 3);
\coordinate [label=left:$d$] (d) at (4.3, 1.3);
\coordinate [label=below:$e$] (e) at (5, 1.3);
\draw[green] (a) -- (b) -- (c) -- (d) -- (e);
\draw[green] (6, 0) -- (6, 6);
\coordinate [label=right:$a'$] (a') at (6, 4);
\coordinate [label=right:$b'$] (b') at (6, 4.5);
\coordinate [label=right:$c'$] (c') at (6, 3);
\coordinate [label=right:$d'$] (d') at (6, 1.3);
\coordinate [label=right:$e'$] (e') at (6, 1.3);
\draw[green] (a) -- (a');
\draw[green] (b) -- (b');
\draw[green] (c) -- (c');
\draw[green] (d) -- (d');
\draw[green] (e) -- (e');
\end{tikzpicture}
\caption{Monotonic polygonal chains}
\label{fig:monotonic_chain}
\end{figure}
经xelatex处理的图形如下:
还有algorithm, algorithmic宏包,用来排版算法伪码效果非常好。我估计<<Introduction to Algorithms>>上的伪码就是用的这个。latex源码如下:
\caption{Determining whether or not P is convex}
\label{alg:convex}
\begin{algorithmic}[1]
\FOR {$i = 1$ to $n$}
\STATE $j \gets i \bmod n$
\STATE $p \gets \overrightarrow{V_{j-1}V_j} \times \overrightarrow{V_{j}V_{j+1}}$
\IF{$p < 0$}
\PRINT "Polygon P is not an convex polygon!"
\RETURN \FALSE
\ENDIF
\RETURN \TRUE
\ENDFOR
\end{algorithmic}
\end{algorithm}
排版效果(博客中上传的图片貌似都有压缩,效果稍差):

昨天无意间又发现了cdlatex这个东西,至此,emacs+cdlatex+auctex+reftex+outline+xetex,这些东西组合起来,感觉写文档非常美妙。在文档中穿梭,有时间,等我通晓elisp后,在来总结这些东西。再上一张图。
这不,今天写实验报告又碰见了数据的图形化,顺便复习下gnuplot。kiss the unix。
下午在老板公司,和学长简单交流了下,自己在一边搞定上网,大概看了下windows ce的东西。不过现在感觉自己最大的软肋还是编程基础和算法基础。看书看书看书。
明天的数值分析,逻辑,后天的计算机组成实验,都是头疼的课。我一向对电类的课程比较头疼。电路原理,数电等硬件类课程无一例外都挂掉了。一方面是自己没好好学,另一方面也是自己实在提不起兴趣。比较讨厌。逻辑实验虽然七搞八搞能做出结果,但是个中详细原理,却懒得去理了,只求用latex把实验报告弄的好看点,祈求得个差不多的分数就行。
C++之父Bjarne Stroustrup的最新力作<<Programming: Principles and Practice Using C++>>,刚翻了翻目录。讲的内容非常广泛。从最初的入门知识,语言结构,面向对象,stl,gui,embedded, testing,不知深度如何。书中前言说:If you work by yourself, don't expec to spend less time than that(maybe 15 hours a week for 14 weeks)。
Unix编程艺术,经典书籍,久闻其名,今天终于狠下心买了一本。当小说来看好了。
越学越不明白。计算机软件简直是无边无际无极的知识海洋。技术的更新,理论的发展,这些独有的特点使得计算机应用科学的知识更新换代极其迅速。我想在大概明白所谓的需求驱动。计算机的学习也是一样,什么样的需求,什么样的技术,用到了再去学,边学边实践。像什么asp pk php等等完全是无聊的东西。有需要就学,没有这个需要的话学了不用也忘掉。当然有些经典的东西,c++, unix, emacs, latex, algorithms, sql, xml, 这才是千秋万代的东西。加油吧,lox。