行者无疆 始于足下 - 行走,思考,在路上
闲谈MapReduce(1): Hadoop初探
Table of Contents
1 缘起
MapReduce是这几年IT界很热的一个名词,从某种意义上讲,MapReduce引领了当代海量数据处理的趋势和潮流。与IT界的其他名词一样,MapReduce听起来也是个很玄乎的名词,MapReduce?Map?Reduce?如果你是一名初级Coder,那么你可能从某处知道,Map的翻译是映射,Reduce的翻译是归约。MapReduce就是映射归约,是一种数据并行处理的一种编程模型。如果很不幸,你不是一名光荣的Coder,只是中国网民大军中的五万万分之一1,那么没关系,MapReduce离你并不遥远,有一个名词你一定很熟悉,那就是——云计算。关于云计算,互联网上有一个经典笑话,“中国一留学生去美国打工的当过报童,不带计算器,习惯动作抬头望天时心算找零。顾客大为惊讶,纷纷掏出计算器验证,皆无误,也抬头望天,惊恐问:“云计算?”不过云计算的真正含义,用工程师的语言,准确地定义,应当是“超大规模的,可扩展的,低成本,但是高可靠性的服务器集群系统”2。
从大的层面上来讲,云计算并不仅仅是MapReduce,MapReduce只是云计算的一个技术性开端,或者说,是互联网的发展需求推动技术的发展进步,最后由Google临门一脚创造出来的一种处理海量数据的并行编程模型。真正的云计算包含诸如IDC建设、海量存储、网络规划、商业模式、网络安全等等诸多技术的难题,还有很多被一些所谓的专家炒作起来的社会意义。不过本系列文章并不打算探讨这些过于宏大的主题,我本人也没有这样的水准和资格来说三到四。本系列文章的目的只有一个,那就是搞明白,MapReduce中的Map和Reduce,到底源自何处3?
我第一次听说MapReduce这个名词,是在2010年9月,那时百度来浙大宣讲,顺带开了一个技术讲座,主讲人徐串曾是Google中国编程挑战赛冠军。当然,讲座内容我是听不懂的,随心记下来的几个技术名词,至今为止,还能记住的,只剩下MapReduce了。后来面试百度运维部,期间和面试官聊到我暑期实习在华数淘宝做的一个视频转码入库系统,面试官大概觉得这个系统有点分布式的意思,因此题目结束的时候给了我一个建议,就是让我学习下MapReduce。再后来,阴差阳错,我进入了百度的分布式运维小组学习Hadoop运维,学习MapReduce就成了一个身不由己的任务。
在百度的半年,我初步接触了大规模Hadoop集群(3000个节点的规模)的运维工作。但比较讽刺的是,运维Hadoop集群的我,自身并没有写过多少真正的MapReduce程序,对Hadoop的理解也浅尝辄止。而我也始终没有搞明白,好端端的一个程序,为什么要按照MapReduce这样别扭的模型重构运行?
大概是看了Paul Graham的《黑客与画家》后,我开始正式认真学习Lisp这门语言,至今已有小半年时间,这期间我利用业余时间,和最近一个月的休假时间,基本上看完了Paul Graham的《ANSI Common Lisp》和《On Lisp》,《SICP》太难,我穷尽脑力至今也只窥得前面三章,做了100道习题左右,不过即便如此,也令我受益匪浅4。半年Lisp的学习让我搞明白了MapReduce中,Map和Reduce的来龙去脉。这个问题我Google了很久,但是始终没有一个满意的答案,现如今,我自己找到了满意的答案。
2 抽象漏洞(兼谈数学和计算机工程)
在正式开始我们的探险之旅前,我们还面临这一个问题,那就是,这次探险的必要性在哪里?既然MapReduce已然为我们提供了成熟的理论编程模型,Hadoop生态圈也给我们提供了一整套成熟的工程实现,我们为什么还要纠缠这些学究般的历史问题?我的解答是, 一个学科的历史往往就是这个学科的本身 。无论是一门编程语言、编程范式、编程模型,或者IT业的任何一项新技术新名词,在学习的过程中,一定要搞明白:
- 它解决了什么样的技术问题?当时的历史背景是什么?还有没有类似的(可能没有流行起来的)解决方案?
- 它的引入带来了哪些新的问题?
- 它的优点是什么?什么样的问题一定会手到禽来?
- 它的不足是什么?什么样的问题是它解决不了的?
这就好比解一道很难数学题,如果光告诉你一个正确的数字,那么这个数字对你来说一点意义都没有;如果进一步,告诉你标准的解题过程,那么你可能会对这个题目有一个粗浅的认识;如果有那么一个白痴,不但告诉你正确的答案和解题过程,还把他的演算纸送给了你,并热切地给你讲解他在解题过程中碰到了哪些问题和陷阱,是怎样解决怎样解决问题怎样规规避这些陷阱的,那么你对这道题目的理解则会大大加深,日后再碰到同样类型的问题就会轻车熟路,手到拈来。 从某种意义上而言,一个完整的解题的探寻过程才是一个题目所具有的全部信息价值,扔掉这些而仅仅记住一个解题结果或者一个标准的解题证明,无疑是买椟还珠 5 。但是比较可悲的是,计算机是一个年轻的学科,所以专门讲述计算机历史的书籍并不像数学史书籍一般汗牛充栋。
从另一个角度上讲,计算机和数学的都是一座不断分层的抽象大厦。数学是从基本的整数,到数系的扩充,到微积分的诞生,到非欧几何等等宏大的诗篇;而计算机则是从最基本的与非门,到bit、byte、word,到汇编、c、高级语言,到设计模式、分布式等等现代工业的大厦和基础。“计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决6”,不过很不幸, 计算机的抽象和数学的抽象有一个本质的不同,那就是计算机的抽象是有漏洞的 ,这就是抽象漏洞法则:All non-trivial abstractions, to some degree, are leaky。在数学领域,我们从来不用担心说某个定理“因为空调故障的原因宕机了,或者因为内存吃紧运行特别缓慢,似乎是发生内存泄漏了”,等等诸如此类的各种各样令人头疼的问题。这条法则深刻的影响了计算机软件和数学定理的生产过程——在计算机中,我们不可能找到一个能困惑世间智者358年的谜7;在数学领域,我们也不可能找到一个耗费人类5000万人年人力的定理8。 如果说,基于抽象的数学,考验的是人类大脑思考深度的极限,那么同样是基于抽象,并且脱胎于数学的计算机工程,挑战的就是人类大脑思考广度的极限 ——软件工程中瓶瓶罐罐的细节太多了,所以大凡软件开发,走的都是兵团作战的策略;而数学就不一样,“10个产妇无法在一个月内生出孩子9”,数学领域中辉煌定理的产出,往往依靠少数几个,甚至单个天才数学家的苦苦思索和灵感涌现。
3 Let's Go
以上,废话了这么多,所要强调的无非就是,了解MapReduce的来龙去脉,对于写出更好的MapReduce程序,甚至将来拨开层层抽象,解决MapReduce的底层问题,乃至改善MapReduce,都是大有裨益的。不过,在正式踏上我们的探险旅程之前,我们需要检查一下手头的“装备”是否合格,很简单:
- 你需要一台*nix系统,最好是GNU Linux,苹果也行,如果实在不方便,Windows下装个Cygwin也还能凑合;
- 你需要有一定的编程经验,包括但不仅限于C、Java、Bash、Python,如果再对Lisp或者Scheme有一定了解就更好了(别急,本系列文章对Lisp做一个简要的介绍);
- 你需要了解一些常见的*nix软件开发工具,包括但不限于Vim的使用、Ant和Make构建工具、Git和SVN版本控制软件;
- 你需要对POSIX系统标准有一定了解,包括但不限于*nix的文件系统结构、用户属组、文件权限、管道等等。
Now, Let's Go!
4 Hadoop
行文至此,相信众位读者已经知晓了云计算的一些基础概念,最起码知道了所谓Google技术的三驾马车是什么,如果能看过Hadoop代码中WordCount的例子并能看懂的话,那你简直是太天才了。为了保证我们的探险顺利进行,我们需要一套开源的MapReduce平台实现来验证我们的学习成果,Hadoop是不二选择。关于Hadoop本身有太多太多的资料,因此我在这里就不再劳心劳力的copy别人的劳动成果了。推荐以下三本书,作为Hadoop的入门:
我们所要做的,就是在本机的*nix系统下,搭建一个demo的伪分布式运行的Hadoop平台。我采用的Hadoop版本是Hadoop 0.20,这个版本比较稳定,最新的Hadoop 1.0添加了很多新的特性,这些特性对于我们的探险并没有特别的作用,而且我也不甚了解。当然,本文的重点并不是Hadoop,所以我并不会带你去分析HDFS的源代码,告诉你如何打Patch(我也不会,嘿嘿)。本文的重点在于MapReduce的来龙去脉。
- 首先本机*nix上存在jdk和ssh,并找到相应的$JAVA_HOME
- 首先是建立本机用户到自身的ssh信任关系,步骤大致如下:
➜ ~ ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/home/lox/.ssh/id_rsa): /home/lox/.ssh/id_rsa already exists. Overwrite (y/n)? y Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/lox/.ssh/id_rsa. Your public key has been saved in /home/lox/.ssh/id_rsa.pub. The key fingerprint is: 19:3f:55:84:99:d2:1e:c6:42:d0:39:6f:3e:83:84:21 lox@lox-pad The key's randomart image is: +--[ RSA 2048]----+ | .+.+ =o | | E . * O. | | ..o B.. | | .+..+ | | S.o+ | | ..+ | | o | +-----------------+ ➜ ~ cp .ssh/id_rsa.pub .ssh/authorized_keys ➜ ~ chmod 700 .ssh ➜ ~ chmod 600 .ssh/authorized_keys ➜ ~ ssh lox@localhost
- 下载hadoop v0.20,解压缩到一个目录,我的目录结构如下,其中tmp/hadoop-data作为hdfs数据存放目录(包括伪分布式运行的namenode和datanode的数据),tmp/hadoop-v20作为$HADOOP_HOME
➜ ~ tree -L 1 tmp/hadoop-data tmp/hadoop-v20 tmp/hadoop-data tmp/hadoop-v20 ├── bin ├── build.xml ├── CHANGES.txt ├── conf ├── conf.origin ├── conf.pseudo ├── conf.standalone ├── contrib ├── docs ├── hadoop-0.20.3-dev-ant.jar ├── hadoop-0.20.3-dev-core.jar ├── hadoop-0.20.3-dev-examples.jar ├── hadoop-0.20.3-dev-streaming.jar ├── hadoop-0.20.3-dev-test.jar ├── hadoop-0.20.3-dev-tools.jar ├── ivy ├── ivy.xml ├── lib ├── LICENSE.txt ├── logs ├── NOTICE.txt ├── README.txt ├── src └── webapps
-
修改hadoop的配置文件分别如下:
- hadoop-env.sh,重点修改下$JAVA_HOME,指向SUN JDK或者OpenJDK的目录,Hadoop官方建议采用SUN(现在是Oracle啦)的JDK。
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
hadoop-env.sh ... ... # The java implementation to use. Required. # export JAVA_HOME=/opt/java export JAVA_HOME=/usr/lib/jvm/java-7-openjdk ... ...
core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/lox/tmp/hadoop-data/tmp</value>
</property>
</configuratione>
hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/lox/tmp/hadoop-data/name</value>
<final>true</final>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/lox/tmp/hadoop-data/data</value>
<final>true</final>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>5</value>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>5</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx512m</value>
</property>
</configuration>
- 启动hadoop,如果能用Hadoop FS Shell做一些常规的mkdir和ls操作,Hadoop搭建就算大功告成了:
➜ ~ hadoop namenode -format 12/02/15 00:07:23 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = lox-pad/127.0.0.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.20.3-dev STARTUP_MSG: build = http://svn.apache.org/repos/asf/hadoop/common/tags/release-0.20.2 -r 916569; compiled by 'lox' on Wed Nov 9 23:40:01 CST 2011 ************************************************************/ Re-format filesystem in /home/lox/tmp/hadoop-data/name ? (Y or N) y Format aborted in /home/lox/tmp/hadoop-data/name 12/02/15 00:07:25 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at lox-pad/127.0.0.1 ************************************************************/ ➜ ~ start-all.sh starting namenode, logging to /home/lox/tmp/hadoop-v20/bin/../logs/hadoop-lox-namenode-lox-pad.out localhost: starting datanode, logging to /home/lox/tmp/hadoop-v20/bin/../logs/hadoop-lox-datanode-lox-pad.out localhost: starting secondarynamenode, logging to /home/lox/tmp/hadoop-v20/bin/../logs/hadoop-lox-secondarynamenode-lox-pad.out starting jobtracker, logging to /home/lox/tmp/hadoop-v20/bin/../logs/hadoop-lox-jobtracker-lox-pad.out localhost: starting tasktracker, logging to /home/lox/tmp/hadoop-v20/bin/../logs/hadoop-lox-tasktracker-lox-pad.out ➜ ~ jps 21061 JobTracker 20852 DataNode 21255 Jps 20977 SecondaryNameNode 20764 NameNode 21156 TaskTracker ➜ ~ hadoop fs -mkdir /tmp/this-is-a-test-dir ➜ ~ hadoop fs -ls /tmp Found 1 items drwxr-xr-x - lox supergroup 0 2012-02-15 00:08 /tmp/this-is-a-test-dir ➜ ~
好了。基础工作已经准备好,在接下来的旅程中,我会初步讲解一下Hadoop的基本概念和使用方法,进而转入Lisp(Scheme)函数式编程的美妙世界,带你逐本溯源,领略一下原生态的Map和Reduce到底是什么模样,并且会顺带谈到一些我在Lisp学习过程中领略到的别样风景,包括但不限于Java的反射、序列化等一些高级特性,XML、JSON的数据语言的特性特点等等。敬请期待!
--
Footnotes:
1 第29次中国互联网络发展状况统计报告显示,2012年初,中国网民共计5.13亿。
2 关于这个定义的出处可以参考弯曲评论上一篇非常好的关于云计算的科普文章“云里雾里云计算”,本文不打算探讨云计算的社会意义、产业变革、安全等过于宏大的主题(其实我对这些一点都不了解)。
3 MapReduce的第一篇论文"MapReduce: Simplified Data Processing on Large Clusters"曾写到:"Our abstraction is inspired by the map and reduce primitives present in Lisp and many other functional languages."可见,MapReduce的思想来自于古老的Lisp语言。
4 广告一下,在我有限的阅读经历中,《SICP》是我读过的计算机书籍中最棒的一本,没有之一。如果能认真做完这本书里面的356道题目,绝对会让你对编程本质的理解有一个脱胎换骨般的提高。这里有我个人的部分习题解答代码和学习笔记。
5 关于这一点,刘未鹏的《知其所以然》系列文章里有更好的解读,我就不再重复了。
8 据《Unix编程艺术》的序言里的脚注:“从1969年到2003年,35年世间并不短。以这期间众多Unix站点数量的历史曲线来估算,人们在Unix系统的开发方面投入了约5000万人年”。
9 这原本是Brooks's Law的一种观点。
兔年伊始
一月初处理完家中的事,回到百度补了三天班,请了两周的假,马不停蹄回到杭州,参加学校的几门考试。当然,这期间顺便去了趟上海看了看妞——也顺便看了看新版水浒传。陪妞的几天搞定了C#大作业,到杭州已经是一月中旬的事情。到宿舍的第一件事是发现了桌子上的奖学金证书,上面还写着自己的名字,没错,就是我。学业优秀三等奖学金,我仔细看着这几个烫金大字,脸上一阵苦笑——要知道,大三一年我还挂了三门课。不过心里却还是挺高兴的,虽然我根本不太在乎这个东西。给母亲打了个电话,让她高兴高兴;给妞也发了条短信,妞回“你的大学生活完满了”——我呢,会心一笑,盘算着这几百大洋能给妞买个什么东西呢。
一月的杭州总是那么阴霾,又赶上难得的大雪给太阳公公放了长假,不多的好心情也在湿冷的空气中散发殆尽。考试还是很无聊的,更无聊的是你在准备无聊的考试,别人却在旁边无聊地玩着无聊的游戏。所谓“大四不考研,天天像过年”,我是个例外,因为大四的最后半年我还有七门考试——都是重修。其实每个学期初自己都雄心勃勃的——工作要好,项目要做好,课程也要尽量做好,但是往往最终结果是工作好,项目好,课程却一塌糊涂。大四上我选了六门课,华数淘宝实习到十月中旬,然后用了不到两周的时间就拿下了Baidu的Offer,照理说,剩下的时间应该好好补补课业,搞一搞毕业设计,结果我却依然非常偏执地申请了Baidu的实习,不断地给自己“没事找事”,不懂得“享受时光”。结果是,整个一个学期六门课,我就去上过两次。学期末的考试自然难免焦头烂额。好在结果还行,我通过了本该预科时学的《线性代数》,两门选修课,C# 80+,软件体系结构也低空飘过。电路原理就去打了个酱油,计算机组成再度弃考,数字电子技术……真是纠结。
在杭州的几日还去参加了两次同学会,最大的发现是,CKC的同学们还是很牛的——有拿到MIT某某比赛金牌的、有在MSRA实习的、有拿了ACM中国赛区金牌+HKUST Offer+MSRA实习的、有保送到ZJU CAD/CG实验室读PHD的、有ibus-cloud-pinyin的作者和ibus-sunpinyin的作者、有主修CS辅修商科最后拿了Monitor咨询Offer的强悍女生,等等。我发现自己似乎有个小毛病,就是太过认可自己的生活方式,总以为别人的生活方式怎样怎样,偶尔会带着一丝鄙夷的眼光来看待一些事情。回头看看自己写的两篇《找工作总结》,霸道之气溢于言表,对自己挂课这件事情不以为耻,反而吹嘘地如同传奇一般。这或许是一种自恋吧。想想还是那句话,“人生不是平行的向量,没有可比性”。每个人都应该有自己的精彩,嗯。
23日回到北京,继续Baidu的实习。由于我元旦、春节等各种假期,导致我在Baidu的时间很分散,因此导师安排我去做一个项目调研性的工作。我选择的是x-trace,一个patch-based、cross-layer的网络监控工具。做的调研工作就是如何在Hadoop中集成x-trace,从而全面了解MapReduce任务的运行细节,如下图:

在Baidu一直奋战到最后一天,还参加了整个运维部的年夜饭。2月2号早晨起床迟了,便转道赶往六里桥客运站。好在运气不错,赶上了家乡的一辆Passat正在吆喝人,简单询问了下就上了车。司机彪悍无比,用一对春联盖上前后的车牌,几百公里的高速公路愣是没有交一分钱。就这样,大年三十、下午两点,我总算有惊无险地回到了家中。家中几日无非就是那么几件事情——看春晚、包饺子、走亲戚、喝大酒。我不喜欢喝酒,虽然我有那么点酒量。我觉得多数情况下,酒杯里盛的不是酒,而是虚伪。觥筹交错的背后往往是尔虞我诈。酒品如人品,都是一种心境,对高人而言,即便是白水一杯,亦可品出人间百态。
8号返京。我和父亲开车,带上弟弟,捎上去廊坊工作的表兄表嫂。带弟弟来主要是让他来参观下,长长见识,按照父亲的说法——“给他施加点压力”。中午到火车站,在北京的立交桥上绕了若干圈后终于到达了北5.4环我的住处。下午去百度大厦参观,节假日,保安无论如何也不给我这个面子,就是不让父亲和弟弟进。无奈之下只能带着他们绕着大厦走了一圈。时间尚早,就临时改变了计划,去清华北大参观下。如此又让我想到了高二那年来北大蹭课的青涩岁月。那时自己一门心思沉浸在竞赛中,数学竞赛惨败后就转战了化学,跟着“师傅”来到了北大,跟老师说是来买些书,顺便来听次课。其实暗地里倒是主要为了逃避一次月考。来到北大,漫步在未名湖畔,仰望博雅塔,清风徐徐,心情自不必说——仿佛自己已经考上北大,成了天之骄子。漫步进入一个小书店,就如那刘姥姥进了大观园,直把这里当成了理工科的天堂。买了各种各样的书,热学的,分析化学的,有机的,不知道有多开心了。次日去化学系蹭了节裴伟伟的有机化学课,讲的是什么已然忘记,印象深刻的,第一点就是很多人上课迟到,或者偷偷吃东西,让我觉得非常不可思议;第二点就是“师傅”wp去索要裴教授的签名,裴问了我们是哪个学校的,“师傅”说是唐山一中高二的……北大蹭完课,晚上又去清华逛了逛,也记不得是从哪个门进去的,只是记得wp总在那里提醒说“清华比北大还大,小心走丢”,还有就是我们逛着逛着到了一个路灯下,杆子上有一个按钮,我就要伸手去摁。然后wp一下子把我从背后抱住。事后我才知道那个可能是报警按钮,不能乱摁。哎,当时实在是太嫩了。
胡乱开车到了清华西门,时间已是下午两点多。在清华只走了两个小时,父亲就直嚷嚷着大腿疼。我也终于明白,父亲的时代已经过去。我们,已经成了时代的主人。清华出来后又拉着俩人去未名湖走了一圈,顺便感慨下即将逝去的大学生涯。晚上带着俩人去看了场3D电影——周杰伦的《青蜂侠》。父亲是一点本事没有了,而他也确实十多年没有看过电影了,像个小孩子似的,跟在我的后边,拿票,换3D眼镜。看了一半他还睡着了……弟弟倒是看得津津有味。
次日早晨,父亲和弟弟回家,我去上班。走之前帮他们设置好了导航仪,一路顺风,中午到家。我回到公司,继续调研我的x-trace。直到现在,项目依然没有本质的进展,主要原因是我对这个项目的难度评估不足,其次是我个人能力不够。x-trace是Berkeley RAD Lab几个博士生的博士论文项目,整个项目涉及到众多领域如对TCP/IP协议栈的深刻理解、Java/Ruby/Perl的纯熟使用等等。除此之外还有一些基础性工具的使用,如svn/git、ant/maven/scons、jetty、graphviz,GNU diff/patch等等,而要结合Hadoop与x-trace,更是需要对Hadoop的内部通讯机制有着深刻的了解。而这一切的一切,让我在调研的过程中举步维艰。
好在导师并没有给我施加太大的压力,项目也没有特别紧要的milestone,所以我还是有时间来巩固下基础,看一些书籍。部分重读了Java之父James Gosling的《The Java Programming Language》,了解了Annotation、Reflection、Serialization,让我对Java语言有了更进一步的认识。不过不得不说,初学者想要靠这本书入门还是太难了。学习了下Ant的使用,简单浏览了下Ant权威指南,主要是了解下主要思想和基本概念,没有太过深究。Hadoop: The Definitive Guide读到了第十章,还在本机上搞了个伪分布式Hadoop集群,但是缺乏实践,对Hadoop内部机制还是似懂非懂,多写写Java程序吧。另外,Pragmatic系列的几本小书都很不错:
- 《Pragmatic Version Control Using Subversion》,svn基础使用入门,有Linux环境的话动手实践一下,两三天就可以上手了。
- 《Pragmatic Unit Testing in Java with JUnit》,基于JUnit 3.x版本的,比较老了,但是单元测试的概念是相通的。
- 《Pragmatic Project Automation》,讲的是软件的自动化构建、测试、安装、发布等等。
技术之外,我还看了一些电影短片和Blog,简单做下推荐:
- 《天使爱美丽》:特别喜欢影片的色调、喜欢那个傻傻的矮个子、玻璃老头,当然,还有爱美丽的微笑。
- 《黑天鹅》:一部心理剧,展示了人在巨大压力下心理的变化过程。但是我看不太懂。
- 姜文《太阳照常升起》、《阳光灿烂的日子》,不知道是姜文的电影太过晦涩,还是我比较幼稚,总是看不太懂,包括《让子弹飞》。当然,字里行间外露的姜文的霸气,我还是能感受得到的。
- 筷子兄弟《老男孩》,也许我还没有长大,不够成熟,但是这个片子让我来评,歌曲占80%,片子占20%。“青春如同奔流的江河,一去不回来不及道别”,叶蓓《白衣飘飘的年代》也是很不错的。
- 旭日阳刚《春天里》、西单女孩《天使的翅膀》:总是有那么一些人,能够不时的带给我们一些温暖和感动,坚持的力量。
-
刘伟《You Are Beautiful》
- “我的人生中只有两条路,要么赶紧死,要么精彩地活着”
- “生命里有三样东西不可以少,空气 水 音乐”
- 《搭车去柏林》,这个记录片看得我躁动不已。我跟妞说“我们辞职吧,用一生的时间去度一个蜜月”。每一刻都是崭新的,我所向往的生活。
- 《背包十年》,号称是中国第一位职业旅行家,确是不一样的人生。但是作者认为“白领的生活精确到每分每秒,但每分每秒都是无聊”,我认为颇为偏激。社会需要进步,而单单靠环游世界是无法推动社会进步的。所以环游世界是我的梦想,但也只是梦想之一。
- 身边总有这么一些人:净干些随意妄为的事,一副既不在乎自己也不在乎别人的样子,其实心底里藏着比任何人都要柔和而耀跟的光芒。还就是这么些人,时不时地让你感到:活着真他妈带劲。follow your heart!!
忙里偷闲还去体验了下Archlinux下WordPress的本机安装,琢磨着有空了去搞一个独立域名的Blog。我最近一直想写一些东西,比如Hadoop的本机安装啊,WordPress的入门使用啊,Subversion使用小记啊,等等,诸如此类。但是转念一想,这些东西在网上都有足够多的资料,也不需要我在多此一举,给互联网上再增添点垃圾信息——国内的很多网站论坛基本上就是Copy来Copy去,而且Copy过来都不懂得排版一下就贴上去,恶心。我更希望有一些深刻独特的东西,所以最近一直在思考,却很少提笔了。如刘未鹏所说,“书写是为了更好的思考”,坚持写了一年多的Blog,确实让我受益很多。一点一滴,看到了自己的成长过程,结交了一些朋友,也开始学着将知识串成网络,展现出来。
3月返校,暂时结束Baidu实习生涯,全力以赴搞定毕业大计。看看能否抽出时间,架上单车,再出去“干上一票”,漂泊的梦想,压抑好久,已经膨胀的不行。

Issues of Eclipse Helios with Hadoop
最近在搞Hadoop MapReduce,在本机配置了个Hadoop Pseudo环境,就琢磨着写两个Java小程序练练手。而Java程序开发的初始配置一向以麻烦著称,记得大二时开始学习Java时对那个CLASSPATH环境变量晕了好久。所以这个时候选一款顺手的IDE就是很重要的了。
另一方面,对于长期生活在K.I.S.S环境的geek来说,对IDE通常是不感冒的。他们更喜欢a+b+c+d+Emacs或者Vim+w+x+y+z的组合。但是Java就不同了。Emacs虽然有JDEE,但是Emacs没有好用的jsp-mode,好像也没有自动打包发布部署的功能,或者即使有,也需要极其麻烦的配置。而且Emacs的代码不全功能一向很麻烦也不太好用,对于Java巨大的类库和超长的类名就更头大了。所以在血淋淋的事实面前,我还是屈服了。好在还有个Eclipse。
为什么是Eclipse而不是NetBeans?其实没啥特别的原因,就是Eclipse的界面更加和谐一点,对Java Swing的丑陋效果和蜗牛般的速度实在是心有余悸。Eclipse确实也是非常优秀的软件,跨平台,多语言,丰富的插件和和谐统一的插件安装系统,良好的社区支持。Emacs也是。
好了,废话少说,说说今天纠结的Eclipse Hadoop之旅吧。我用的软件版本是Eclipse 3.6,安装的时候顺便将eclipse-cdt也装上了:
pacman -S eclipse eclipse-cdt
启动Eclipse一切正常,试着建立一个Project却发现无论如何也找不到C++的项目,照理说不应该,不过不打紧,C++和今天的主题无关。继续。
Eclipse开发Hadoop MapReduce程序需要安装一个hadoop eclipse plugin,而根据Eclipse和Hadoop版本不同,所需选择的插件也不一样,有官方hadoop contrib里的jar包,有google code上的,还有打过patch的山寨jar包。而eclipse安装插件的方法也有很多,比如:
- 安装到plugins目录
- 安装到dropins目录
- links方式安装
- 通过Help-->Install New Software的方式安装
- ……
而我排列组合搞了一个下午后,Eclipse 3.6的Hadoop插件还是没有装上。无奈在AUR上安装了Eclipse 3.5:
yaourt -S eclipse-classic-galileo
然后将eclipse-hadoop-plugin放到plugins目录下,终于看到了可爱的小象。究竟是怎么回事呢?
定位好久,还是没有任何头绪。首先是eclipse没有Linux Manual,输入eclipse --help也没有任何信息,所以我不知道eclipse CLI有没有什么可用的参数;其次是我不知道eclipse有没有自己的log,或者有我也不知道在什么位置,无法发现启动过程中的蛛丝马迹。
此时已经有些心灰意冷,寻思着要不就用Eclipse 3.5得了。无意中在网上发现了Hadoop的另一个插件,Karmasphere,看了下介绍还是蛮强大的,而且有community和professional两个版本,前者是免费的,只是下载的时候需要简单注册下。最重要的是,这个插件有Eclipse和NetBeans两个版本,真实太令人激动了。照着教程配只好NetBeans 6.9的开发环境,可以用,很强大。于是心情大好,继续配置Eclipse 3.6版本,这下Eclipse 3.6无法安装插件的问题终于露出了狐狸尾巴:
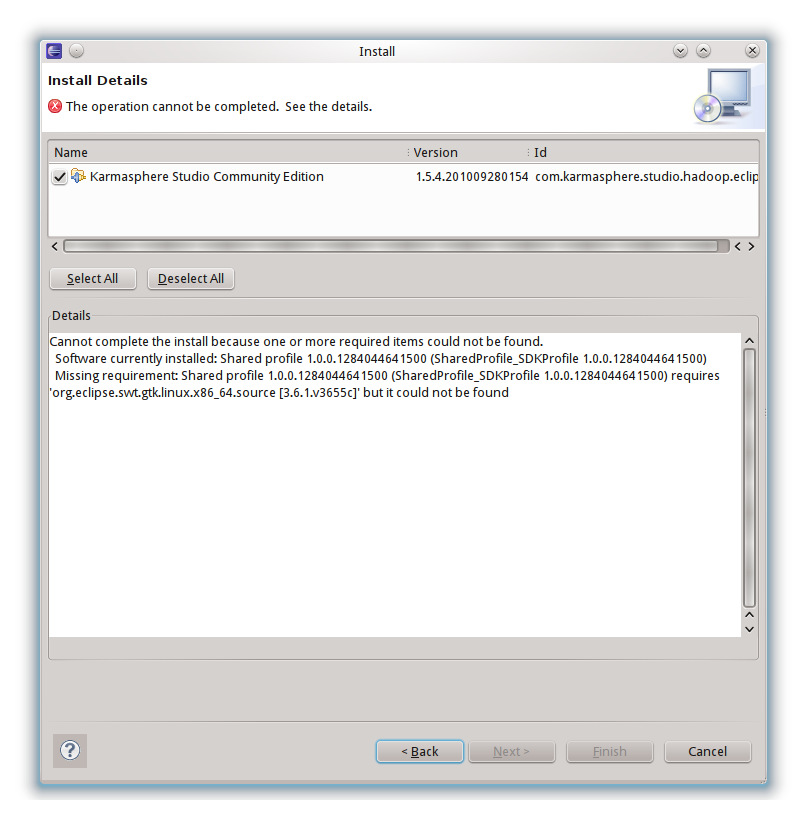
重点是"requires 'org.eclipse.swt.gtk.linux.x86_64.source [3.6.1.v3655c]' but it could not be found"。赶紧定位下org.eclipse.swt.gtk.linux.x86_64:
% sudo updatedb && locate org.eclipse.swt.gtk.linux.x86_64 /usr/share/eclipse/plugins/org.eclipse.swt.gtk.linux.x86_64.source_3.6.1.v3655c.jar /usr/share/eclipse/plugins/org.eclipse.swt.gtk.linux.x86_64_3.6.1.v3655c.jar
可以肯定的推断,这个东东在系统中是存在的,虽然命名方式可能不太一样。接下来的问题就好办了很多。我怀疑是/usr/share/eclipse目录的读写权限问题。在这里我的想法得到了佐证。于是立马改了/usr/share/eclipse的读写权限:
sudo chown -R lox:users /usr/share/eclipse
重启Eclipse 3.6,果不其然,CDT复活了。于是又安装了Eclipse-hadoop-plugin和karmasphere的plugin,总算大功告成。
最后放一张图吧: